Frequently Asked Questions
This section contains answers to the common questions that new developers to Boost often have.
Topics
-
- Note
-
The code in these topics was written and tested using Microsoft Visual Studio (Visual C++ 2022, Console App project) with Boost version 1.88.0.
C++ Library Programming
-
What is involved in using a Boost header-only library?
After installing the Boost libraries, not much, just include the libraries you want. Here is an example (
example1.cpp) using Boost.Multiprecision:#include <boost/multiprecision/cpp_dec_float.hpp> #include <iostream> // Alias for a high-precision floating-point type using namespace boost::multiprecision; using BigFloat = cpp_dec_float_50; int main() { BigFloat a = 1.0 / 3.0; BigFloat b = sqrt(BigFloat(2)); // Note that setprecision has been specified as slightly longer than the floating point numbers std::cout << "1/3 with high precision: " << std::setprecision(51) << a << std::endl; std::cout << "Square root of 2: " << std::setprecision(51) << b << std::endl; return 0; }Compile with:
g++ -std=c++17 example1.cpp -o example1No linking is required, just run the program!
-
What is involved in using a Boost compiled-binary library?
Using a compiled-binary library involves linking to the library, and any dependent libraries that are also compiled. Here is an example (
example2.cpp) using Boost.Filesystem.#include <boost/filesystem.hpp> #include <iostream> #include <fstream> namespace fs = boost::filesystem; int main() { fs::path filePath("example.txt"); if (fs::exists(filePath)) { std::cout << "File exists: " << filePath.string() << std::endl; } else { std::cout << "File does not exist, creating it..." << std::endl; std::ofstream file(filePath.string()); file << "Hello, Boost.Filesystem!"; file.close(); } return 0; }This requires an extra step before running, linking to both Boost.Filesystem and Boost.System. We need to link to Boost.System because Boost.Filesystem calls
boost::system::generic_category()- for error handling - and this call is only defined in the compiled version of Boost.System:g++ -std=c++17 example2.cpp -o example2 -lboost_filesystem -lboost_systemNow you can run your program.
- Notes
-
The example compiler used here is GNU C++. If you are using the Clang compiler, simply replace
g++withclang++. On macOS, if Boost is installed via Homebrew, you might need to specify the paths further:clang++ -std=c++17 example2.cpp -o example2 -I/usr/local/include -L/usr/local/lib -lboost_filesystem -lboost_systemIf you are using MSVC, and the libraries are in the default path, then the command would be:
cl /std:c++17 example2.cpp /Fe:example2.exe /link boost_filesystem.lib boost_system.lib
-
Given a choice, when should I use header-only or compiled-binary libraries?
Depends on your priorities:
Priority Header-Only Compiled-Binary Ease of Use
Yes - Easier (just include)
No - Requires linking
Compilation Time
No - Slower
Yes - Faster
Binary Size
No - Larger (possible code duplication)
Yes - Smaller
Performance
Yes - Optimized via inlining
Yes - Optimized via specialized builds
Portability
Yes - Highly portable
No - Requires platform-specific builds
Debugging
No - Harder (complex errors with templated code)
Yes - Easier
ABI Stability
No - Less stable
Yes - More stable
Also, with a header-only library the compiler has full visibility of the code, allowing inlining and optimizations that might not be possible with separately compiled binaries. This can reduce function call overhead when optimizations are applied. Since no precompiled binaries are needed, projects using header-only libraries are easier to distribute and deploy.
However, header-only libraries are compiled within each project, so any minor changes (even updates) can lead to unexpected behavior due to template changes. Shared libraries with well-defined Application Binary Interfaces (ABIs) offer better versioning control.
Header-only libraries are certainly easier to get going with. To optimize for better stability and debugging, and reducing binary size, refer to the next few questions on how to create binaries for header-only code - typically, when your project is becoming stable.
-
Can I use C++20 Modules to precompile header-only libraries and import them when needed?
Not reliably or consistently. Boost libraries are not currently written as C++20 modules. They use traditional headers, macros, and complex template structures that don’t cooperate well with the C++20 export module syntax.
As a workaround, consider using old-fashioned header files. For example, for
boost_module.hpp:#pragma once #include <boost/multiprecision/cpp_dec_float.hpp> using BigFloat = boost::multiprecision::cpp_dec_float_50;Then for the main code:
#include "boost_module.hpp" #include <iostream> int main() { BigFloat x = 1.0 / 3.0; std::cout << "1/3 with high precision: " << std::setprecision(51) << x << std::endl; return 0; }Even if Boost were module-friendly,
cpp_dec_float_50is a template instantiated from a header, and exporting it in a module interface would require exposing a lot of detail that header-only libraries don’t support out of the box. -
Can I create a Static Library from header-only libraries and link when needed?
Yes, even if the library is header-only, you can wrap it in a
.cppfile, compile it into a static.aor.libfile, and link it. Start by creating a wrapper source file (boost_wrapper.cpp) that includes the header-only Boost libraries:#include <boost/multiprecision/cpp_dec_float.hpp> boost::multiprecision::cpp_dec_float_50 dummy_function() { return 1.0 / 3.0; // Forces compilation of template instantiation }Now, compile it into a static library:
g++ -c boost_wrapper.cpp -o boost_wrapper.o ar rcs libboost_wrapper.a boost_wrapper.oUse it in your code:
#include <boost/multiprecision/cpp_dec_float.hpp> #include <iostream> int main() { boost::multiprecision::cpp_dec_float_50 x = 1.0 / 3.0; std::cout << "1/3: " << x << std::endl; return 0; }Compile and link:
g++ main.cpp -L. -lboost_wrapper -o main- Note
-
One advantage of this approach is it avoids re-parsing and re-instantiating templates in every translation unit.
-
Can I create a precompiled header (PCH) that imports Boost libraries?
Yes, a precompiled header should enable faster recompilation when only the main code changes. And, unlike modules, it works in older C++ versions.
For example, create an hpp file (boost_pch.hpp) containing the required libraries:
// boost_pch.hpp #include <boost/multiprecision/cpp_dec_float.hpp>Precompile it into a
.gchfile:g++ -std=c++17 -x c++-header boost_pch.hpp -o boost_pch.hpp.gchUse it in your code:
#include "boost_pch.hpp" // Uses precompiled header int main() { boost::multiprecision::cpp_dec_float_50 x = 1.0 / 3.0; std::cout << "1/3: " << x << std::endl; return 0; }Typically, when your project starts becoming "large" use of compiled libraries becomes more relevant.
-
In the programming world, what qualifies as a small, medium, or large project?
While not perfect, lines of code is a quick way to classify project sizes:
Project Size Lines of Code Estimate Small
less than 10,000
Medium
10,000 to 100,000
Large
100,000 to 1,000,000
Enterprise/Monolithic
more than 1,000,000
Or possibly classify a project by the number of developers:
Project Size Developers Small
less than 5
Medium
6 to 50
Large
51+
Enterprise/Monolithic
Hundreds, across multiple time-zones
There are other metrics too - if your incremental build takes minutes, it’s getting large. If a full rebuild takes hours, it’s definitely a large project. If the dependency tree is deep, requiring fine-grained modularization, it’s large.
- Note
-
Size alone is not a perfect measure of complexity. A templated metaprogramming-heavy project might be "large" in complexity but only a few thousand lines. Or a UI-heavy application might have tons of boilerplate but be relatively simple. Boost Libraries are available to help prevent a "large" project becoming a "beast"!
-
When does a coding project become a "beast"?
A coding project becomes a beast when two or more of the following conditions are met:
-
Build times are measured in coffee breaks - if compiling takes longer than making (and drinking) a cup of coffee, it’s a beast!
-
When you start considering distributed builds or caching everything, it’s serious.
-
No one developer knows how everything works anymore.
-
The project is in "dependency hell" - adding one more library requires resolving a cascade of conflicts. Or, you start saying, "Do we really need this feature?" just to avoid the dependency headache.
-
Debugging feels like archaeology - code from years ago still exists, but no one remembers why. Or, comments like
// DO NOT TOUCH - IT JUST WORKSlitter the source code. -
Refactoring is a nightmare - a simple rename breaks hundreds of files, or "Let’s rewrite it from scratch" starts sounding reasonable.
-
Multi-minute CI/CD pipelines - your test suite takes longer to run than a lunch break.
-
Contributors live in fear of merge conflicts.
-
CMake
-
Can I build Boost libraries using the tool CMake and what documentation resources are available to help with this?
Yes, CMake is a popular tool to use in conjunction with the Boost libraries.
In this User Guide, refer to the examples in Getting Started and in Building with CMake.
The Boost CMake support infrastructure has a lot of good information in it too.
-
Am I right that the alternative to using CMake to build Boost is the B2 tool?
Correct. Refer to Getting Started for examples, and B2 for a full specification.
-
Do I need to set BOOST_ROOT?
Usually not — CMake can often find Boost automatically. However, if Boost is installed in a non-standard location, call
cmake -DBOOST_ROOT=/<PATH-TO-BOOST>or addset(BOOST_ROOT "/PATH-TO-BOOST")in your CMake file. This is especially useful when working with custom-built Boost versions. -
Any good advice if CMake fails to find Boost components?
Set the flag
-DBoost_DEBUG=ONto print detailed search diagnostics. -
If I want to install and build all of Boost using CMake, what would the command be?
Try:
cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=<target-dir> -DBOOST_INCLUDE_LIBRARIES=serialization <path-to-boost-root-folder> && cmake --build . --target install --config Release -
If I include a single library I want to use in my CMake build file, will dependent libraries automatically be built too, or do I have to include them explicitly?
You do not usually have to include dependent libraries in your CMake file if you use the
target_link_librariescommand. For example, if you just wanted to build Boost.Filesystem, then add the following to your file:find_package(Boost REQUIRED COMPONENTS filesystem) target_link_libraries(my_app PRIVATE Boost::filesystem)However, if you use the
add_subdirectoryoption in CMake, you will need to specify individual dependent libraries. Use the Boostdep tool to provide a list of all dependencies. Refer to Boost CMake support infrastructure for details.
Combining Libraries
-
Can you give me some examples of Boost libraries that developers have found work well together?
Many Boost libraries are designed to be modular, yet complementary, and over the years, developers have discovered powerful combinations of libraries that work well together. Here are some groups:
-
If you are building an Asynchronous Networking Stack, then the following libraries mesh naturally: Boost.Asio for core asynchronous I/O and networking, Boost.System for error codes that are used in Asio error handling, Boost.Thread or Boost.Fiber for managing threads or fibers in concurrent code, Boost.Chrono for working with timeouts and deadlines, and Boost.Bind or Boost.Function for callbacks and handler binding in Asio.
If the network supports financial systems, in particular high-frequency trading, then add Boost.Lockfree to support low-latency data structures, and Boost.Multiprecision for high-precision arithmetic.
-
Say you are working on Compile-Time Metaprogramming and Reflection, then the following libraries enable expressive and powerful template code, with strong introspection and static analysis at compile time, reducing runtime cost: Boost.Hana or Boost.Mp11 for high-level metaprogramming, Boost.Fusion provides sequence manipulation for structs and tuples at compile time, Boost.TypeTraits for query and transform types, and Boost.StaticAssert or Boost.Assert to validate assumptions during compile-time logic.
-
A quite different field is Simulation, Geographic Information Systems (GIS), Robotics, and CAD. For this you need accurate, type-safe modeling of space, motion, and physical quantities, all interoperable in simulations or mathematical domains. The following provide this: Boost.Geometry for the algorithms in 2D/3D spatial operations, Boost.Units for strongly-typed physical units to prevent dimensional errors, Boost.Qvm for lightweight vector and matrix algebra, Boost.Math adds special functions, statistical distributions, numerical accuracy, and Boost.Numeric/interval can represent ranges of values that may contain uncertainty. In robotics in particular, you might need Boost.Thread to support parallel sensor processing. Also, Boost.Serialization might also help with state persistence.
-
If you are building a Test Suite, say with unit testing and regression tests, consider adding to Boost.Test the following: Boost.TypeTraits to inspect and verify types in test cases, Boost.Optional or Boost.Variant or Boost.Outcome to represent and test optional or alternative outcomes, Boost.Preprocessor to generate test cases or datasets at compile time, and finally Boost.Format or Boost.Locale for diagnostics, error reporting, and internationalized tests.
-
On a similar vein to testing is Logging. Logging infrastructure is well supported by Boost.Log. Boost.PropertyTree might help with configuration and data trees, Boost.CircularBuffer for bounded memory logging, and Boost.ProgramOptions for a command-line interface (perhaps for embedded systems).
-
As a final example consider Saving/Restoring State, Remote Procedure Calls (RPC), Configuration Files, Distributed Systems. The following collection covers all aspects of data flow - loading, storing, transforming, and parsing—all in a type-safe, extensible style: Boost.Serialization for the core for serializing C++ objects to/from streams, Boost.Variant or Boost.Optional to serialize complex, dynamic types, Boost.PropertyTree for easy access to config files (JSON, XML, or INI) and Boost.Spirit for parsing domain-specific formats into structured data.
For deeper examples of multiple libraries, including working source code, refer to Common Scenarios and Advanced Scenarios.
-
-
I want to build a cross-platform system, right from the start. What libraries should I use as core to that system?
Desktop applications like text editors, project managers and utilities often need cross-platform compatibility, user input processing, and dynamic plugins via signal-slot mechanisms. Consider Boost.Filesystem to provide the file management, Boost.Locale for use in multiple regions, Boost.Signals2 to support an event system, and Boost.Regex for structured text parsing.
-
Are there any combinations of Boost libraries that experience has shown do not play well together?
Not in a broad sense, Boost C++ libraries are designed with a high degree of interoperability. However, there are always nuances when multiple libraries have overlapping functionality, conflicting macros, or different assumptions about thread safety, memory management, or initialization. Issues can usually be avoided with careful design, for example:
-
Boost.Signals2 internally uses Boost.Thread for managing asynchronous signal connections. However, there have been instances where thread safety issues arise when these two libraries are used in parallel. If not handled properly, it can lead to deadlocks or race conditions, especially in multithreaded environments. Always ensure that signals are disconnected properly and thread-safe operations are applied where needed.
-
Both Boost.Filesystem and Boost.Regex perform some filesystem operations and string manipulation that can lead to conflicts when used in combination, especially if Regex is processing filenames or paths that contain special characters (for example, slashes or backslashes in Windows paths). When working with filenames and regular expressions, it’s best to sanitize the inputs carefully before passing them on.
-
Boost.Mp11 and Boost.Hana both work with metaprogramming, often with overlapping functionality, but their usage patterns can conflict. MP11 uses a more classic, compile-time only, and more explicit metaprogramming model, while Hana includes both compile-time and runtime metaprogramming functions, which introduce ambiguity when mixing the two libraries. Best to choose one of these libraries, unless you can ensure clean separation between the two.
-
The interaction between Boost.Serialization (for serializing and deserializing objects) and Boost.Python (for integrating C++ code with Python) can be tricky when serializing Python objects. Issues like memory management conflicts or incorrect serialization of Python objects can occur, especially with Python’s dynamic typing system. Wrapping Python objects in C++ classes with explicit serialization mechanisms may be necessary.
-
When using asynchronous I/O with Boost.Asio and regular expressions with Boost.Regex, conflicts can arise, particularly with blocking operations in
boost::asio::io_serviceorboost::asio::strand. Regex can be CPU-intensive and might block the main event loop of Asio, leading to performance issues or deadlocks. Use non-blocking or asynchronous alternatives (separate threads) for Regex operations in the context of Asio. -
Boost.Pool is a custom memory pool allocator that can cause issues when used with Boost.SmartPtr (such as
boost::shared_ptrorboost::scoped_ptr) since these smart pointers manage memory differently. The interaction between custom memory pools and reference-counted pointers can lead to memory leaks or double-free errors if not handled correctly. When using Pool with smart pointers, ensure that custom allocators are compatible with the reference-counting behavior of smart pointers. Consider usingboost::shared_ptrwithboost::pool_allocatorif you’re using custom memory pools. -
Both Boost.Spirit (a parsing library) and Boost.Serialization involve significant template metaprogramming, which can result in large compile times and potential conflicts in template instantiations. The combination of these libraries in the same project can exacerbate compilation times and, in rare cases, cause conflicts in template instantiation or symbol resolution. Use these libraries in different parts of your project and limit cross-dependencies.
-
Boost.Test is a robust testing framework, while Boost.Thread is used for threading. Problems can occur if your tests are not properly isolated from thread contexts, or if tests involving multiple threads cause race conditions or deadlocks that aren’t immediately visible. Use proper synchronization techniques in multi-threaded tests to avoid race conditions. When testing threaded code, use the correct testing tools provided by Test, such as
BOOST_THREAD_TEST, to ensure proper isolation of tests and reduce flaky test results.In general, to avoid problems, always test combinations of libraries early, to ensure proper synchronization and error handling.
-
-
Is there a checklist to work through to ensure I have covered my bases when combining libraries?
The following checklist should be a good start:
Boost C++ Library Integration Checklist
-
Build and Linking
-
Confirm which Boost components are header-only vs require linking.
-
Use a consistent Boost version across the codebase.
-
Link required Boost libraries explicitly (for example,
-lboost_filesystem,-lboost_thread). -
Use CMake’s
find_package(Boost REQUIRED COMPONENTS …)correctly if applicable.Dependencies and Size
-
Audit transitive dependencies with tools like the Boost Copy Tool (bcp) and Boost Dependency Report.
-
Include only the headers you need to keep compile times fast and code lean.
Preprocessor Macros
-
Check for key macros like
BOOST_NO_EXCEPTIONS,BOOST_ASSERT,BOOST_DISABLE_ASSERTS. -
Avoid macro name collisions (for example,
bind,min,max) by careful header ordering or#undef.Thread Safety
-
Ensure Boost libraries used are thread-safe in your usage context.
-
Use thread-safe variants (Boost.Signals2, Boost.Log with thread-safe sinks) as needed.
Clean Code Practices
-
Encapsulate low-level Boost operations behind clean APIs.
-
Apply RAII for all resource management (files, sockets, locks).
-
Handle exceptions and error codes consistently across Boost modules.
Debugging and Tooling
-
Prepare for template error verbosity (for example, with Boost.Spirit, Boost.Mp11, Boost.Hana).
-
Verify debug symbol generation and stack traces involving Boost types.
Documentation and Discoverability
-
Document Boost macros and configuration choices in the build setup or source files.
-
Link to official Boost documentation: https://www.boost.org/doc/libs/.
Testing and CI
-
Add unit tests for modules using Boost.
-
Test both success and failure paths (for example, file-not-found, timeout, parsing errors).
-
Test across multiple Boost versions/platforms if possible in CI pipelines.
Integration with Other Libraries
-
Watch for macro conflicts or settings when combining Boost with libraries like Qt, Poco, OpenCV.
-
Guard against duplicate symbols or conflicting linkage when using static/shared Boost libs.
Refer also to Boost Macros and Customize Builds to Reduce Dependencies.
-
Compatibility
-
Can I use Boost with my existing C++ project?
Yes, Boost is designed to work with your existing C++ code. You can add Boost libraries to any project that uses a compatible C++ compiler. The big three compatible compilers are Microsoft Visual C++ on Windows, Clang especially for the macOS, and GCC, the GNU Compiler Collection, mostly on Linux. Other lesser used compilers that will work well include the Intel Compiler and MinGW - Minimalist GNU for Windows.
-
Can I use Boost libraries with the new C++ standards?
Yes, Boost libraries are designed to work with modern C++ standards including C++11, C++14, C++17, C++20, and C++23.
-
What flavors of Linux are supported by the Boost libraries?
Boost libraries are generally compatible with most Linux distributions, provided that the distribution has an up-to-date C++ compiler. This includes:
-
Ubuntu
-
Fedora
-
Debian
-
CentOS
-
Red Hat Enterprise Linux
-
Rocky Linux / AlmaLinux
-
Arch Linux
-
openSUSE
-
SUSE Linux Enterprise
-
Slackware
-
Gentoo
-
Cray Linux
-
HPC cluster Linux
-
macOS
Boost also works on embedded Linux, including:
-
Yocto Linux
-
Buildroot
-
Raspberry Pi OS (Debian based)
Be aware with embedded systems there might be issues such as toolchain availability and available RAM during compilation.
-
-
How can I be sure that a library I want to use is compatible with my OS?
While Boost strives to ensure compatibility with a wide range of compilers and systems, not every library may work perfectly with every system or compiler due to the inherent complexities of software. The most reliable source of information is the specific Boost library’s documentation.
Conferences
-
What are the main C++ conferences where I will learn the most about the language and libraries?
The largest conference each year is CppCon, currently held in September in Aurora, Colorado. Talks typically include library authors and standards contributors.
Smaller, deeply technical, and perhaps with more hallway style conversations is Cpp Now. Held in May, in Aspen, Colorado. This conference started as BoostCon. A good event for meeting Boost library authors.
In Berlin, Germany, typically in early November, there is Meeting C++, one of Europe’s largest with a practical approach to modern programming and tooling.
Also in Europe, there is the ACCU Conference, recently held in Folkestone, UK, in June. The focus here is on best practices of software engineering.
These are the big four conferences each year. The ISO Cpp Working Group meetings occur three times per year (typically March, June, November), and the location rotates around the globe. This event is where the language standard is defined and updated. Refer to the FAQ on ISO C++ Committee Meetings.
There are also some regional events that might work well.
The using std::cpp conference in Spain in March has a strong technical focus and is popular amount European developers.
Also in Europe and in March, there is the BeCPP Symposium in Belgium.
In Asia, the C++ Summit is held in Shanghai, typically in November though the times can vary.
If you attend several conferences, you may well find projects debut at one of the smaller conferences before a more polished presentation is given at CppCon.
-
Is there such a thing as online C++ conferences?
Yes, not free but there is Cpp Online.
Constexpr
-
Why is there so much online chat about the C++ term
constexpr?constexprlets you run real C++ programs during compilation, not just when the program runs. By declaring functions asconstexprthey are run at compile time, often to produce look-up tables that are blindingly fast to execute at runtime. For example:struct Entry { uint64_t hash; int id; }; constexpr auto build_table() { std::array<Entry, words.size()> table{}; for (size_t i = 0; i < words.size(); ++i) { table[i] = { hash_str(words[i]), static_cast<int>(i) }; } // compile-time sort (yes, really) std::ranges::sort(table, {}, &Entry::hash); return table; } constexpr auto lookup_table = build_table();At runtime the binary will contain something like the following:
constexpr Entry lookup_table[] = { {0x1234..., 0}, {0x2af3..., 1}, {0x88ab..., 2}, ... };This means that at runtime there is no parsing, no hashing, no sorting, no allocations - just a table look-up. Simply, anything done at compile time costs zero runtime CPU. It’s one of the biggest long-term evolutions in the language.
-
How does
constexprimprove program safety?By using
constexpryour program will often fail at compilation if something is wrong, and not at runtime. For example, invalid configuration, out-of-range values, bad lookup tables, and broken assumptions will often appear as compile time errors. -
How does
constexprcompare withconstevel?A
constexprfunction can run at compile-time, or can run at runtime. Aconstevalfunction must run at compile-time.constevalis perfect for compile-time string hashing, generating IDs, reflection helpers, and for building static lookup tables.constexpris the more powerful as it gives you compile-time when possible, runtime when needed. -
What is the history of
constexpr?A table shows the developing nature of this concept:
Standard What changed C++11
constexprintroduced (very limited)C++14
Loops and more logic allowed
C++17
More library support
C++20
Dynamic allocation, containers, algorithms
C++23
Ever more library functions become
constexprC++26
Huge expansion — reflection and "constexpr everywhere"
-
What applications typically use the
constexprapproach?Apps where performance is king: game engines, compilers, serialization libraries, networking protocols, embedded systems, to name a few.
-
What Boost libraries take advantage of the power of
constexpr?Over the last 5 to 10 years, many Boost libraries have been heavily modernized to exploit
constexpr, it’s siblingconsteval, and compile-time metaprogramming. A modern Boost-heavy project can parse URLs, generate serializers, build type-safe APIs, and compute math tables - all at compile time. For example:-
Boost.Hana : The flagship
constexprmetaprogramming library, built around compile-time computation, type-level programming, andconstexprcontainers and algorithms - such as filters, transforms, folds, sorts. -
Boost.Mp11 : Ultra-fast constexpr template metaprogramming.
-
Boost.Describe : Provides
constexprreflection. You can iiterate fields at compile time, generate serializers, generate UI bindings, build ORM mapping, and auto-generate JSON - all viaconstexprmetadata. -
Boost.Pfr : Provides
constexprreflection without macros, and iterate, serialize, and compare structs at compile time. -
Boost.StaticString : Enables
constexprstrings. -
Boost.URL : Designed so some parsing can run at compile time.
-
Boost.Json : Uses
constexprfor lookup tables, parsers, and optimized state machines. -
Boost.Container : Steadily becoming more
constexpr-capable. -
Boost.Math : Huge portions now support compile-time evaluation of constants, special functions, numeric limits, and lookup tables.
-
Coroutines
-
When reading about coroutines, I often come across the term
task. Within the context of C++, is a task a function or process?A
taskis a coroutine object representing an asynchronous operation that will eventually produce a result. A normal function runs immediately and returns a value. Ataskis a coroutine that will produce a value later when awaited. In simple terms it is a lazy async function call that hasn’t run yet (a paused function call). The name was chosen as it is the same concept as anasync taskin Rust, or anasyncio Taskin Python. -
How does a coroutine
taskcompare withstd::future<T>?The concepts are similar in that they both represent a value that will exist later. However
std:futureis thread-based, and the result retrieved usingfuture.get()- which will block other code until the value is retrieved. Ataskis event-loop/coroutine based, does not require its own thread, is retrieved usingco-await task- and critically this is a non-blocking call - other code will keep running. -
When should I consider using coroutine tasks and when standard future constructs?
If the coding scenario you are building is heavily into CPU parallelism, or a simple background job, then
std::futureand a thread model is probably your best bet. If your scenario is high-scale networking, say involving millions of operations, then tasks and coroutines should provide a solid solution. -
What are the core constructs of Boost.Asio, I believe a super-popular networking library?
Yes Boost.Asio is a very popular networking library. It’s core constructs are an event loop (an
io_context), async operations, completion handlers, executors, strands, I/O objects, and buffers. It is certainly not based on futures and threads, though they are optional usage styles.- Note
-
A
strandguarantees that handlers do not run concurrently.
-
Is it true that coroutines can never block, or get caught up in race conditions?
No. A coroutine is a state machine that can suspend and resume. Nothing about it automatically guarantees safety. Care has to be taken with coroutines not to be, for example, providing wrappers around blocking calls or wrappers around CPU-heavy work hidden inside the coroutine. And as for race conditions, coroutines do not imply mutual exclusion, atomicity, serialization, nor thread-safety.
Coroutines are scheduling points - they guarantee that execution can be suspended and resumed, and that no thread is blocked whilst awaiting async I/O. Using coroutines still requires good practices around shared objects. Coroutines make asynchronous code look sequential, but they do not remove concurrency — so all normal rules about blocking and race conditions still apply.
-
Has anyone come up with a good design methodology for coroutines, such as graphs of state machines, or flow diagrams of some sort?
This has become an active design space, because once you move from “functions” to “suspended state machines”, you naturally start needing different mental models. There isn’t one single universally accepted methodology, but there are strong, widely used approaches that map very well to coroutines. The most popular in practice are Sequence Diagrams, for example:
Coroutine io_context Timer | | | |--- async_wait --->| | | |--- register --->| | (suspend) | | | | | | | time passes | | | | |<-- resume --------|<-- ready -------| | | |A sequence diagram answers the questions - who is doing what, who resumes me, what thread am I on?
Another approach is a Structured Concurrency Graph, where you model coroutines as a task tree, for example:
Parent task / \ / \ child A child B | | await await \ / \ / completionThis approach helps you reason on cancellation propagation, lifetime, error propagation, and task ownership.
Other approaches that have proved helpful include Control-Flow Graphs where nodes are execution blocks and edges are control flow or suspend/resume transitions. State Machine diagrams may also help, in that almost every coroutine boils down to a state machine with suspension points as states. Something else to consider is Actor-style models where coroutines are treated as message-driven state machines (actors). This actor-based approach has found success in game engines and high-concurrency servers.
In the real world of coroutine programming - most bugs come from not modelling coroutines explicitly at all!
-
In the world of coroutines, what is meant by a "promise", and what would an example function look like?
There is confusion over the use of the word "promise", as a coroutine "promise object" is certainly not the same thing as a
std:promisefrom<future>. The promise object is a compiler-generated control object that manages the coroutine’s state, results, suspension, and lifetime. Here is a minimalistic but runnable example - noting thatpromise_typeis a sub-struct ofTask:#include <coroutine> #include <iostream> // -------------------------------------------------- // Coroutine return object // -------------------------------------------------- struct Task { // ===================================================== // A minimal promise type contains the following 5 calls // ===================================================== struct promise_type { // Called when the coroutine object is created, and returns the parent Task Task get_return_object() { return {}; } // Suspend immediately at start? std::suspend_never initial_suspend() { return {}; } // Suspend at end? std::suspend_never final_suspend() noexcept { return {}; } // Handles co_return; void return_void() { std::cout << "co_return happened\n"; } // Handles uncaught exceptions void unhandled_exception() { std::terminate(); } }; }; // -------------------------------------------------- // Coroutine function // -------------------------------------------------- Task example() { std::cout << "Inside coroutine\n"; co_return; // Invokes promise.return_void() } int main() { example(); }Note: When compiling this sample, a modern compiler is recommended (Visual Studio 2022, GCC 12, Clang 15, or later), and make sure to set the C++ compiler standard to C++20, or later. In Microsoft Visual Studio, for example, locate the project properties:
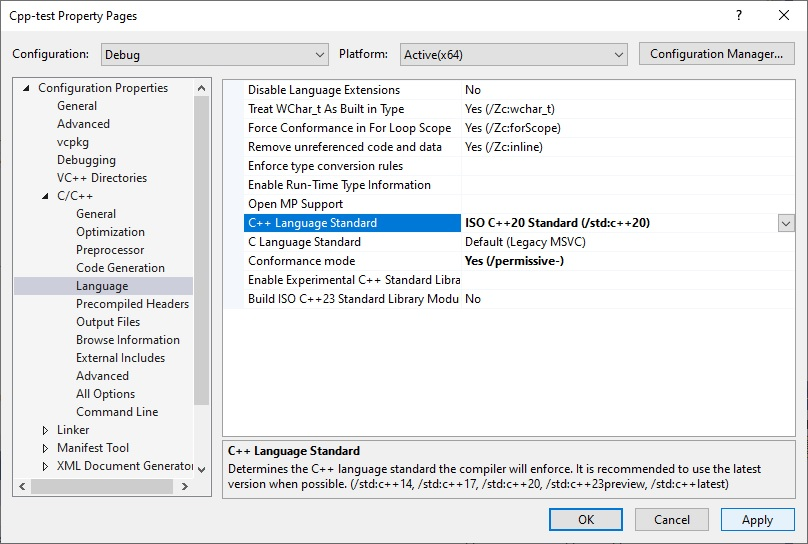
Don’t confuse the promise type with
std::promise- which ia a thread-to-thread value delivery mechanism. -
Am I right that the
co_awaitfunction handles suspension and resumption?Yes,
co_awaitworks by calling three methods (await_ready,await_suspend,await_resume) that together control whether and how a coroutine pauses and resumes, for example:#include <coroutine> #include <iostream> // -------------------------------------------------- // A minimal awaiter // -------------------------------------------------- struct SimpleAwaiter { // Should we suspend? bool await_ready() const noexcept { return false; } // Called when suspending void await_suspend(std::coroutine_handle<> h) const { std::cout << "Coroutine suspended\n"; // Immediately resume for demo purposes h.resume(); } // Value returned from co_await void await_resume() const noexcept { std::cout << "Coroutine resumed\n"; } }; // -------------------------------------------------- // Minimal coroutine return type // -------------------------------------------------- struct Task { struct promise_type { Task get_return_object() { return {}; } std::suspend_never initial_suspend() { return {}; } std::suspend_never final_suspend() noexcept { return {}; } void return_void() { } void unhandled_exception() { std::terminate(); } }; }; // -------------------------------------------------- // Coroutine function // -------------------------------------------------- Task example() { std::cout << "Before co_await\n"; co_await SimpleAwaiter{}; std::cout << "After co_await\n"; } // -------------------------------------------------- // main() // -------------------------------------------------- int main() { example(); } -
How do I code a coroutine to produce a single value in the future, then close down?
A
co_returncommunicates with the coroutine’s promise object to produce a single value. For example, the following code returns an integer:#include <coroutine> #include <iostream> // -------------------------------------------------- // Coroutine return object // -------------------------------------------------- struct Task { struct promise_type { int value; // Create return object Task get_return_object() { return Task{ std::coroutine_handle<promise_type>::from_promise(*this) }; } // Start immediately std::suspend_never initial_suspend() { return {}; } // Suspend at end so result can be read std::suspend_always final_suspend() noexcept { return {}; } // Called by: co_return int; void return_value(int v) { value = v; } void unhandled_exception() { std::terminate(); } }; // Store coroutine handle std::coroutine_handle<promise_type> handle; // Constructor Task(std::coroutine_handle<promise_type> h) : handle(h) { } // Destructor ~Task() { handle.destroy(); } // Access returned value int result() const { return handle.promise().value; } }; // -------------------------------------------------- // Coroutine function // -------------------------------------------------- Task compute() { std::cout << "Inside coroutine\n"; co_return 101; } // -------------------------------------------------- // main() // -------------------------------------------------- int main() { Task task = compute(); std::cout << "Returned value: " << task.result() << "\n"; } -
How do I code a coroutine to produce a series of values, suspending after each value is released?
The key construct to continuous delivery is
co_yield; this pauses the coroutine and returns a value to the caller, but keeps the coroutine alive for later resumption. For example:#include <coroutine> #include <iostream> // -------------------------------------------------- // Generator type // -------------------------------------------------- struct Generator { struct promise_type { int current_value; Generator get_return_object() { return Generator{ std::coroutine_handle<promise_type>::from_promise(*this) }; } std::suspend_always initial_suspend() { return {}; } std::suspend_always final_suspend() noexcept { return {}; } // Handles co_yield std::suspend_always yield_value(int value) { current_value = value; return {}; } void return_void() {} void unhandled_exception() { std::terminate(); } }; std::coroutine_handle<promise_type> handle; explicit Generator(std::coroutine_handle<promise_type> h) : handle(h) {} ~Generator() { if (handle) handle.destroy(); } // Move to next value bool next() { if (!handle || handle.done()) return false; handle.resume(); return !handle.done(); } // Get current value int value() const { return handle.promise().current_value; } }; // -------------------------------------------------- // Coroutine producing values // -------------------------------------------------- Generator counter(int start, int end) { for (int i = start; i <= end; ++i) { co_yield i; // <-- THIS is the key point } } // -------------------------------------------------- // main() // -------------------------------------------------- int main() { auto gen = counter(1, 5); while (gen.next()) { std::cout << gen.value() << "\n"; } }If you run this code, you should get:
1 2 3 4 5It might help to think of
co_yieldas a lazy generator, only returning values when asked. They are useful when streaming data. parsing token streams, working with async data pipelines, and efficient generators of data in game engines. -
Is an
awaitableobject more efficient than astd:futureobject?Depends on the use-case, but a coroutine awaitable object is non-blocking, does not require its own thread, there is no polling and no explicit shared state.
An
awaitable<T>is a Boost.Asio coroutine-based asynchronous return type that allows functions to produce values later, delivered seamlessly viaco_await. The following example uses a timer to simulate async work:#include <boost/asio.hpp> #include <iostream> using namespace boost::asio; using namespace std::chrono_literals; // -------------------------------------------------- // Coroutine returning a value (awaitable<int>) // -------------------------------------------------- awaitable<int> delayed_value(int v) { auto executor = co_await this_coro::executor; steady_timer timer(executor); timer.expires_after(1s); co_await timer.async_wait(use_awaitable); co_return v * 3; // <-- returns into awaitable<int> } // -------------------------------------------------- // Caller coroutine // -------------------------------------------------- awaitable<void> consumer() { std::cout << "Requesting value...\n"; int result = co_await delayed_value(111); std::cout << "Got result: " << result << "\n"; } // -------------------------------------------------- // main() // -------------------------------------------------- int main() { io_context io; co_spawn(io, consumer(), detached); io.run(); }If you run this code, you should get:
Requesting value... Got result: 333 -
What is considered best practices for instrumenting a coroutine based program - what should be logged?
Instrumenting coroutine-based code is a little different from instrumenting traditional synchronous code because control flow becomes non-linear. For long-running or important coroutines, log "coroutine x started" and "coroutine x completed". And don’t forget errors "coroutine x failed: timeout". The most valuable information in coroutine systems is often before and after
co_await. Cancellation is frequently overlooked, make sure to log concellation requests, cancellation observed, and probably a cleanup complete message too. This is enormously helpful when investigating shutdown issues.For performance-based instrumentation, obviously add accurate timing to your logs, such as "Socket read completed in 2.1 ms".
Large coroutine systems become nearly impossible to diagnose without corelation IDs - IDs that connect sockets, databases, timers and worker pools. A corelation ID should be generated and logged along with coroutine events such as requests, queueing or waiting, completion, response sent. Coroutine systems often hide queueing, so it will be helpful to have logs of "queued for 18 ms" and " exectured for 2 ms" - obviously to help you identify bottlenecks. Tracing resource ownership has also proved to be of value, as coroutines often make resource lifetimes less obvious because ownership spans suspension points.
Consider not logging every suspend/resume event, as this will very quickly become noise.
For Boost.Asio applications specifically, a common best practice is to trace:
-
Coroutine start/end
-
Every significant
co_awaitof I/O operations -
Executor transitions (post, dispatch, thread-pool hops)
-
Exceptions and cancellations
-
Timing information around each awaited operation
-
A request/session correlation ID carried through the coroutine chain
Those six categories typically provide most of the diagnostic value with relatively little logging overhead.
-
Debugging
-
What support does Boost provide for debugging and testing?
Boost provides Boost.Test for unit testing, which can be an integral part of the debugging process. It also provides the Boost.Stacktrace library that can be used to produce useful debug information during a crash or from a running application. Refer also to Category: Correctness and testing.
-
How do I enable assertions in Boost?
Boost uses its own set of assertion macros. By default,
BOOST_ASSERTis enabled, but if it fails, it only callsabort(). If you defineBOOST_ENABLE_ASSERT_HANDLERbefore including any Boost header, then you need to supplyboost::assertion_failed(msg, code, file, line)andboost::assertion_failed_msg(msg, code, file, line)functions to handle failed assertions. -
How can I get a stack trace when my program crashes?
You can use the Boost.Stacktrace library to obtain a stack trace in your application. You can capture and print stack traces in your catch blocks, in signal handlers, or anywhere in your program where you need to trace the execution path.
-
Can I use Boost with a debugger like GDB or Visual Studio?
Yes, Boost libraries can be used with common debuggers like GDB or Visual Studio. You can set breakpoints in your code, inspect variables, and execute code step by step. Boost doesn’t interfere with these debugging tools.
-
Are there any debugging tools specifically provided by Boost?
Boost doesn’t provide a debugger itself. The libraries tend to make heavy use of assertions to catch programming errors, and they often provide clear and detailed error messages when something goes wrong.
-
What are best practices when using Boost Asserts?
Boost provides the assertion
boost::assert. Best practices when using this are:-
Use Assertions for Debugging and Development: Boost assertions should primarily be used during the debugging and development phase of your application. Assertions are designed to catch programming errors, not user errors.
-
Assert Conditions That Should Never Occur: You should only assert conditions that you believe can never occur during normal operation of your application. If there’s a chance that a condition may occur, handle it as an exception or error rather than asserting.
-
Provide Meaningful Assert Messages: Boost assertions allow you to provide a message alongside your assertion. Use this feature to provide meaningful context about why an assertion failed.
-
Consider Performance Impact: Boost assertions can slow down your application. In performance-critical code, consider disabling them in the production version of your application.
-
-
What is the recommended approach to logging, using
boost::log?-
Use Severity Levels: Boost.Log supports severity levels, which you can use to categorize and filter your log messages. This can help you control the amount of log output and focus on what’s important.
-
Provide Context: Boost.Log allows you to attach arbitrary data to your log messages, such as thread IDs, timestamps, or file and line information. Use this feature to provide context that can help you understand the state of your application when the log message was generated.
-
Use Asynchronous Logging: If logging performance is a concern, consider using the asynchronous logging feature. This allows your application to continue executing while log messages are processed in a separate thread.
-
Format Your Log Output: Boost.Log supports customizable log formatting. Use this feature to ensure that your log output is easy to read and contains all the information you need.
-
Handle Log Rotation: If your application produces a lot of log output, consider setting up log rotation, which is supported. This ensures that your log files don’t grow indefinitely.
-
Dependencies
-
What is meant by a "dependency" and the phrase "dependency chain"?
In the context of this FAQ, a dependency is any other library, Boost or Standard or third-party, that a Boost library requires. A primary dependency is a library the top-level library explicitly includes, a secondary dependency is a library that one of the primary, or other secondary dependency, includes.
Boost libraries are modular, but they can depend on each other for various functionalities - for example, Boost.Asio relies on Boost.System for error codes.
In general, taking dependencies can add a lot of value and reduce development time considerably. Boost libraries are carefully reviewed and tested to minimize dependency issues.
As often with powerful concepts, there are pitfalls. Dependencies can lead to "dependency chains," where including one library pulls in others that may not be needed by your project.
-
What issues do library developers have to address when managing dependencies?
This includes handling several awkward situations: Version Conflicts - when different dependencies require incompatible versions of the same library, Transitive Dependencies - when a library pulls in additional, indirect dependencies that you may not even realize are part of your project, Bloat - when the sheer number of dependencies makes the build or runtime environment large, slow, or error-prone, and Security Risks - when outdated or unnecessary dependencies introduce vulnerabilities.
In forum posts you might come across the following phrases, each describing a frustration with dependencies:
-
"Dependency creep" - the gradual accumulation of dependencies over time, often unnecessarily.
-
"Library fatigue" - the exhaustion or frustration of constantly managing and keeping track of too many libraries.
-
"Transitive dependency nightmare" - specifically refers to the frustration caused by indirect dependencies that you don’t directly control.
-
"Package spaghetti" or "Dependency spaghetti" - a messy tangle of interconnected dependencies.
-
"Build chain chaos" - can refer to the difficulties in managing the build process when dependencies are involved.
-
-
What is meant by a "standalone" library?
A standalone library is one where there are no dependencies (or, in reality, few), or the library depends only on the C++ Standard Library. Sometimes separate standalone versions of specific libraries are available, though they might be lightweight versions and not have parity of functionality with the non-standalone version.
-
What can I do to minimize the number and impact of dependencies?
A simple question but with a non-trivial answer. Consider working through this list of strategies and carefully applying when you can:
-
Avoid including headers that aren’t directly needed. When building Boost with B2, you can exclude certain parts of Boost to minimize dependencies. For example, use the
--with-[library]flag to build only the libraries you need. Say you only want Boost.System and Boost.Filesystem, then enter:./b2 --with-system --with-filesystem. This will install only these two libraries, and their essential dependencies. Refer to Building with CMake if you are using CMake as your build tool. -
Read the library documentation to find macros that are available to remove unneeded functionality. For example, when using Boost.Asio, if support for timers or SSL are unneeded, then enter the statement:
#define BOOST_ASIO_DISABLE_SSL. Refer to Customize Builds to Reduce Dependencies for many more examples. -
For powerful libraries like Boost.Asio, you can include only the headers you need, such as
<boost/asio/io_context.hpp>rather than its parent<boost/asio.hpp>. -
Use forward declarations where possible instead of including full headers.
-
Use a C++ Standard Library alternative if one exists, and has equivalent functionality and performance. For example, Boost.Variant could be replaced with
std::variant. -
Use the Header-Only Mode (where possible). Many Boost libraries are header-only, meaning they don’t require linking against precompiled binaries or additional dependencies. Examples include Boost.Optional, Boost.Variant, and Boost.TypeTraits. For details of the binary requirements of Boost libraries refer to Required Compiled Binaries and Optional Compiled Binaries. For example, Boost.Asio has both header-only and compiled modes and you can configure it to work as header-only by defining the macro:
#define BOOST_ASIO_SEPARATE_COMPILATION. -
For experienced developers only, consider commenting out unused code. This approach is possible but risky because it modifies library source code (Boost libraries are open-source), making updates and maintenance more challenging. It involves first identifying the parts of the library that introduce unnecessary dependencies and then commenting out the sections of source code or headers that you don’t need (such as unused features, optional functionality, error handling code). Finally, rebuild the library and check it compiles and links and runs without unwanted side-effects.
-
-
Are there any tools specific to Boost that help manage dependencies?
Yes, the Boost Copy Tool (bcp) is designed to help with dependency management. It allows you to extract a subset of the libraries and their dependencies into a separate directory, minimizing what gets pulled into your project. Install the tool and run
bcp [library-name] [output-dir]. Review the output directory to ensure that only the necessary dependencies are included. For example, if you’re using Boost.Regex, enterbcp regex ./boost_subsetand review the contents of your./boost_subsetdirectory.There is also the Boost Dependency Report, which goes into detail on the primary and secondary dependencies of all the libraries.
-
Are there generally available tools that help with dependency issues?
You can use static analysis tools, like Clang-Tidy or Cppcheck, to analyze your application and see which parts of any dependency are actually being used. Once identified, you can both remove unnecessary headers or dependencies, and perhaps rewrite portions of your code to avoid unnecessary functionality.
Documentation
-
Who writes the documentation for a Boost library?
The library authors are responsible for all the documentation specific to their library. The authors are clearly the most knowledgeable on the design decisions, architecture, API calls, inner workings, and potential limitations of their library. Contributor guidelines on documentation help maintain consistency in styling and content across the library collection. Refer to Documentation Guidelines.
-
If I find an issue with the documentation, or would like to suggest an improvement, can I make a formal request?
Yes you can, file an issue on the library. Typically library authors welcome feedback that enhances the useability of their work - refer to Reporting Issues.
-
Has any Boost library documentation been translated into languages other than English?
There is no formal localization of library documentation. However, translation efforts have existed at various times for Japanese, Chinese and Russian. Most current effort is into Japanese - refer to boostjp.
-
If I wanted to translate my favorite library documentation into my native language, who do contact to get started?
The copyright ownership of library documentation remains with the documentation authors. Contact the authors via the Boost Developers Mailing List if you are inspired to take on this task.
-
Have there ever been efforts to localize not just the documentation but the API calls themselves?
Not for the Boost libraries. Microsoft did experiment with localized API calls many years ago, though the project was abandoned as way too complicated, unmaintainable, and not particularly useful.
Graphics and Games
-
If I wanted to use the Boost libraries in conjunction with a graphics library, to write a 3D game, what graphics library would be most compatible with Boost?
The following libraries work well with Boost because they don’t impose custom build systems or incompatible runtime dependencies — they’re just C++ libraries, and that’s exactly Boost’s domain.
Graphics Library Why It’s Compatible with Boost Ideal Boost Libraries to Pair Modular, C++03/11 compatible, uses STL-style containers and patterns similar to Boost
Boost.Filesystem, Boost.SmartPtr, Boost.Signals2, Boost.Asio
Minimal dependencies, works well with Boost threading and filesystem
Modern, header-only components, great for C+17 and fits Boost idioms
Easy to integrate with Boost for physics, networking, or file I/O
Boost helps manage complexity: asynchronous loading, configuration, math, logging
-
What would be the simplest solution to 3D graphics and Boost working in harmony?
Probably the Ogre3D graphics library, working with Boost.Filesystem for asset control and Boost.Asio for networking.
-
What games systems are well matched with Boost libraries?
Here’s how Boost might slot into a 3D game engine:
System Boost Library Purpose Asset Loading
Cross-platform file handling
Entity Updates
Event-driven game logic
Network Multiplayer
Async client/server or peer/peer communication
Configuration
Game settings, config files
Logging
Diagnostics and crash reporting
Physics or AI Math
Physics, spatial logic
Texture/Image Manipulation
Procedural textures, screenshots
Multithreading
Game loop or rendering pipeline parallelism
-
Are there any graphics libraries that are problematic when combined with Boost libraries?
Both Qt and Unreal Engine are heavy frameworks that conflict with Boost’s philosophy - they replace parts of the STL and introduce their own type systems, both of which can cause serious compatibility issues. Also, DirectX libraries might limit your portability and don’t align well with Boost’s cross-platform goals.
ISO C++ Committee Meetings
-
Who can attend ISO C++ Committee meetings?
Members of PL22.16 (the INCITS/ANSI committee) or of JTC1/SC22/WG21 - The C++ Standards Committee - ISOCPP member country committee (the "national body" in ISO-speak), can attend the meetings. You can also attend as a guest, or join in remotely through email. For details and contact information refer to Meetings and Participation.
INCITS has broadened PL22.16 membership requirements so anyone can join, regardless of nationality or employer, though there is a fee. Refer to Apply for Membership.
It is recommended that any non-member who would like to attend should check in with the PL22.16 chair or head of their national delegation. Boosters who are active on the committee can help smooth the way, so consider contacting the Boost developers' mailing list providing details of your interests.
-
When and where are the next meetings?
There are three meetings a year. Two are usually in North America, and one is usually outside North America. See Upcoming Meetings. Detailed information about a particular meeting, including hotel information, is usually provided in a paper appearing in one of mailings for the prior meeting. If there isn’t a link to it on the Meetings web page, you will have to go to the committee’s C++ Standards Committee Papers page and search a bit.
-
Is there a fee for attending meetings?
No, but there can be a lot of incidental expenses like travel, lodging, and meals.
-
What is the schedule?
The meetings typically start at 9:00AM on Monday, and 8:30AM other days. It is best to arrive a half-hour early to grab a good seat, some coffee, tea, or donuts, and to say hello to people.
Until the next standard ships most meetings are running through Saturday, although some end on Friday. The last day, the meeting is generally over much earlier than on other days. Because the last day’s formal meeting is for formal votes only, it is primarily of interest only to actual committee members.
Sometimes there are evening technical sessions; the details aren’t usually available until the Monday morning meeting. There may be a reception one evening, and, yes, significant others are invited. Again, details usually become available Monday morning.
-
What actually happens at the meetings?
Monday morning an hour or two is spent in full committee on admin trivia, and then the committee breaks up into working groups (Core, Library, and Enhancements). The full committee also gets together later in the week to hear working group progress reports.
The working groups are where most technical activities take place. Each active issue that appears on an issues list is discussed, as are papers from the mailing. Most issues are non-controversial and disposed of in a few minutes. Technical discussions are often led by long-term committee members, often referring to past decisions or longstanding working group practice. Sometimes a controversy erupts. It takes first-time attendees awhile to understand the discussions and how decisions are actually made. The working group chairperson moderates.
Sometimes straw polls are taken. In a straw poll anyone attending can vote, in contrast to the formal votes taken by the full committee, where only voting members can vote.
Lunch break is an hour and a half. Informal subgroups often lunch together; a lot of technical problems are discussed or actually solved at lunch, or later at dinner. In many ways these discussions involving only a few people are the most interesting. Sometimes during the regular meetings, a working group chair will break off a sub-group to tackle a difficult problem.
-
Do I have to stay at the venue hotel?
No, and committee members on tight budgets often stay at other, cheaper, hotels. The venue hotels are usually chosen because they have large meeting rooms available, and thus tend to be pricey. The advantage of staying at the venue hotel is that it is then easier to participate in the off-line discussions, which can be at least as interesting as what actually happens in the scheduled meetings.
-
What do people wear at meetings?
Programmer casual. No neckties to be seen.
-
What should I bring to a meeting?
It is almost essential to have a laptop computer. There is a meeting wiki and there is internet connectivity. Wireless connectivity has become the norm.
-
What should I do to prepare for a meeting?
It is helpful to have downloaded the mailing or individual papers for the meeting, and to have read any papers you are interested in. Familiarize yourself with the issues lists. Decide which of the working groups you want to attend.
-
What is a "Paper"?
An electronic document containing issues, proposals, or anything else the committee is interested in. Very little gets discussed at a meeting, much less acted upon, unless it is presented in a paper. Papers are available to anyone. Papers don’t just appear randomly; they become available four (lately six) times a year, before and after each meeting. Committee members often refer to a paper by saying what mailing it was in, for example: "See the pre-Redmond mailing."
-
What is a "Mailing"?
A mailing is the set of papers prepared before and after each meeting, or between meetings. It is physically just a .zip or .gz archive of all the papers for a meeting. Although the mailing’s archive file itself is only available to committee members and technical experts, the contents (except copies of the standard) are available to all as individual papers. The ways of ISO are inscrutable.
-
What is a "Reflector"?
The committee’s mailing lists are called "reflectors". There are a number of them; "all", "core", "lib", and "ext" are the main ones. As a courtesy, Boost technical experts can be added to committee reflectors at the request of a committee member.
Libraries
-
What are smart pointers in Boost?
Smart pointers are a feature of C++ that Boost provides in its Boost.SmartPtr library. They are objects that manage the lifetime of other objects, automatically deleting the managed object when it is no longer needed. See the Smart Pointers section.
-
Does Boost provide a testing framework?
Yes, Boost.Test is the unit testing framework provided by Boost. It includes tools for creating test cases, test suites, and for handling expected and unexpected exceptions. Refer to Testing and Debugging.
-
What is Boost.Asio?
Boost.Asio is a library that provides support for asynchronous input/output (I/O), a programming concept that allows operations to be executed without blocking the execution of the rest of the program.
-
What is Boost.MP11?
Boost.Mp11 (MetaProgramming Library for C++11) is a Boost library designed to bring powerful metaprogramming capabilities to C++ programs. It includes a variety of templates that can be used to perform compile-time computations and manipulations. Refer to Metaprogramming.
-
Does Boost provide a library for threading?
Yes, Boost.Thread provides a C++ interface for creating and managing threads, as well as primitives for synchronization and inter-thread communication. In addition, Boost.Atomic provides atomic operations and memory ordering primitives for working with shared data in multi-threaded environments. Boost.Lockfree provides lock-free data structures and algorithms for concurrent programming, allowing multiple threads to access shared data concurrently without explicit synchronization using locks or mutexes. For a lighter approach to multi-threading, consider Boost.Fiber. Fibers offer a high-level threading abstraction that allows developers to write asynchronous, non-blocking code with minimal overhead compared to traditional kernel threads.
-
What is the Boost Spirit library?
Boost.Spirit is a library for building recursive-descent parsers directly in C++. It uses template metaprogramming techniques to generate parsing code at compile time. Refer to Metaprogramming.
-
I like algorithms, can you pique my interest with some Boost libraries that support complex algorithms?
Boost libraries offer a wide range of algorithmic and data structure support. Here are five libraries that you might find interesting:
-
Boost.Graph: This library provides a way to represent and manipulate graphs. It includes algorithms for breadth-first search, depth-first search, Dijkstra’s shortest paths, Kruskal’s minimum spanning tree, and much more.
-
Boost.Geometry: This library includes algorithms and data structures for working with geometric objects. It includes support for spatial indexing, geometric algorithms (like area calculation, distance calculation, intersections, etc.), and data structures to represent points, polygons, and other geometric objects.
-
Boost.Multiprecision: If you need to perform computations with large or precise numbers, this library can help. It provides classes for arbitrary precision arithmetic, which can be much larger or more precise than the built-in types.
-
Boost.Compute: This library provides a C++ interface to multi-core CPU and GPGPU (General Purpose GPU) computing platforms based on OpenCL. It includes algorithms for sorting, searching, and other operations, as well as containers like vectors and deques.
-
Boost.Spirit: If you’re interested in parsing or generating text, this library includes powerful tools based on formal grammar rules. It’s great for building compilers, interpreters, or other tools that need to understand complex text formats.
-
-
I am tasked with building a real-time simulation of vehicles in C++. What Boost libraries might give me the performance I need for real-time work, and support a simulation?
Refer to Real-Time Simulation.
-
Which of the open source molecular modelling libraries work well with the Boost C++ libraries, for adding additional functionality such as cooperative design or persistent storage?
There are several high-quality open source projects whose designs and APIs play well with Boost — especially when you want to add capabilities such as:
-
cooperative design / coroutine-oriented workflows
-
persistent storage and versioning
-
extensible geometry and topology
-
strong numerics and precision
-
interoperability with other C++ systems
Projects to look at include:
Name Description A general-purpose cheminformatics toolkit for reading, writing, and converting molecular formats, handling atom pairs, fingerprints, properties, etc. It has a header-only friendly designs that is easy to combine with Boost.Geometry and Boost.Serialization.
A mature C++ cheminformatics and modeling library widely used in computational chemistry and machine learning workflows. RDKit has a pure C++ core with Python bindings, so Boost can extend it without Python. Should work well with Boost.PropertyTree and Boost.Accumulators.
A GPU-accelerated library for molecular dynamics (part of SimTK). Uses POD (plain old data) structures, making them easy to adapt to Boost.Container. Workflows built around tasks can be coroutine-ified for cooperative pipelines, and its data analysis map nicely to Boost.Math.
Industry-strength molecular dynamics library originally in C; now multiple C++ wrapper layers exist. Molecules and topology data can be wrapped into Boost.Geometry point types and distributed simulation can use Boost.Mpi (Message Passing Interface) for cooperative cluster jobs.
-
Licensing
-
What is the license for Boost libraries?
Most Boost libraries are licensed under the The Boost Software License (BSL), a permissive free software license that allows you to use, modify, and distribute the software under minimal restrictions. It is not a requirement for a library to be licensed under the BSL, but its license must meet the License Requirements. Refer to the documentation or source code of any specific library to determine which license applies.
-
Can I use the Boost Logo, after I have built software using the Boost libraries, to help promote my product?
Only with written permission from The Fiscal Sponsorship Committee. For full details refer to Logo Policy and Media Guide.
Metaprogramming
-
What is metaprogramming in the context of Boost C++?
Metaprogramming is a technique of programming that involves generating and manipulating programs. In the context of Boost and C++, metaprogramming often refers to template metaprogramming, which uses templates to perform computations at compile-time.
-
What is Boost.MP11?
Boost.Mp11 is a Boost library designed for metaprogramming using C++11. It provides a set of templates and types for compile-time computations and manipulations, effectively extending the C++ template mechanism.
-
What can I achieve with Boost.MP11?
With Boost.Mp11, you can perform computations and logic at compile-time, thus reducing runtime overhead. For example, you can manipulate types, perform iterations, make decisions, and do other computations during the compilation phase.
-
What is a
typelistand how can I use it with Boost.MP11?A
typelistis a compile-time container of types. It’s a fundamental concept in C++ template metaprogramming where operations are done at compile time rather than runtime, and types are manipulated in the same way that values are manipulated in regular programming.In the context of the Boost.Mp11 library, a
typelistis a template class that takes a variadic list of type parameters. Here’s an example:#include <boost/mp11/list.hpp> using my_typelist = boost::mp11::mp_list<int, float, double>;In this example,
my_typelistis atypelistcontaining the typesint,float, anddouble. Once you have atypelist, you can manipulate it using the metaprogramming functions provided by the library. For example:#include <boost/mp11/list.hpp> #include <boost/mp11/algorithm.hpp> using my_typelist = boost::mp11::mp_list<int, float, double>; // Get the number of types in the list constexpr std::size_t size = boost::mp11::mp_size<my_typelist>::value; // Check if a type is in the list constexpr bool contains_double = boost::mp11::mp_contains<my_typelist, double>::value; // Add a type to the list using extended_typelist = boost::mp11::mp_push_back<my_typelist, char>; // Get the second type in the list using second_type = boost::mp11::mp_at_c<my_typelist, 1>;In these examples,
mp_sizeis used to get the number of types in the list,mp_containschecks if a type is in the list,mp_push_backadds a type to the list, andmp_at_cretrieves a type at a specific index in the list. All these operations are done at compile time. -
What are some limitations or challenges of metaprogramming with Boost.MP11?
Metaprogramming with Boost.Mp11 can lead to complex and difficult-to-understand code, especially for programmers unfamiliar with the technique. Compile errors can be particularly cryptic due to the way templates are processed. Additionally, heavy use of templates can lead to longer compile times.
Other challenges include lack of runtime flexibility, as decisions are made at compile time. And perhaps issues with portability can occur (say, between compilers) as metaprogramming pushes the boundaries of a computer language to its limits.
| Boost.Mp11 supersedes the earlier Boost.Mpl and Boost.Preprocessor libraries. |
Modular Boost
-
What is meant by "Modular Boost"?
Technically, Modular Boost consists of the Boost super-project and separate projects for each individual library in Boost. In terms of Git, the Boost super-project treats the individual libraries as submodules. Currently (early 2024) when the Boost libraries are downloaded and installed, the build organization does not match the modular arrangement of the Git super-project. This is largely a legacy issue, and there are advantages to the build layout matching the super-project layout. This concept, and the effort behind it, is known as "Modular Boost".
Refer to the Super-Project Layout topic (in the Contributor Guide) for a full description of the super-project.
-
Will a Modular Boost affect the thrice-yearly Boost Release?
No. The collection of libraries is still a single release, and there are no plans to change the release cadence.
-
Will this require that the current Boost source structure is changed?
Yes. Unfortunately there is one restriction that adhering to a modular Boost requires - there can be no sub-libraries. That is, we can’t support having libraries in the
root/libs/<group name>/<library>format. All libraries must be single libraries under theroot/libsdirectory. There’s only a handful of libraries that currently do not conform to this already (notably theroot/libs/numeric/<name>group of libraries). -
Why do we want a Modular Boost?
It’s easier on everyone if we adopt a flat hierarchy. The user will experience a consistent process no matter which libraries they want to use. Similarly for contributors, the creation process will be consistent. Also, tools can be written that can parse and analyze libraries without an awkward range of exceptions. This includes tools written by Boost contributors. For example, the tools that are used to determine library dependencies. And any tool that a user might want to write for their own, or shared, use.
Other advantages of a modular format include:
-
Users of Boost can now choose to include only the specific modules they need for their project, rather than downloading and building the entire Boost framework. This can significantly reduce the size of the codebase and dependencies in a project, leading to faster compilation times and reduced resource usage.
-
Individual modules can be updated and released on their own schedule, independent of the rest of the libraries. This allows for quicker updates and bug fixes to individual libraries without waiting for a full release.
-
The structure aligns well with package managers like Conan, vcpkg, or Bazel, making it easier to manage Boost libraries within larger projects. Users can specify exactly which Boost libraries they need, and the package manager handles the inclusion and versioning.
-
-
Will the proposed changes be backwards-compatible from the user’s perspective. In particular, the public header inclusion paths will still be <boost/numeric/<name>.hpp> rather than, say, <boost/numeric-conversion/<name>.hpp>, correct?
Correct - backwards-compatibility should be maintained.
-
When will Modular Boost be available to users?
An exact timeline requires issues to be resolved, though later in 2024 is the current plan-of-record.
Numbers
-
Are there any Boost libraries that extend floating point precision, and at what cost?
In C++, the precision of
floatanddoubletypes is determined by the IEEE 754 standard for floating-point arithmetic, which is used by nearly all modern compilers and hardware. Afloat(with 24 significant bits) is accurate to about 6 or 7 decimal places, adouble(53 significant bits) to 15 to 17 decimal digits. A long double (80+ significant bits) extends this to 18 to 21 decimal digits.Boost does not replace these types, but extends your range of options using Boost.Multiprecision. There are the predefined types
cpp_dec_float_50andcpp_dec_float_100, and the unlimited typecpp_dec_float_<N>, where you decide the value of N.cpp_dec_float_50would obviously give 50 digits, andcpp_dec_float_201gives 201 digits. For example:#include <boost/multiprecision/cpp_dec_float.hpp> #include <iostream> using namespace boost::multiprecision; int main() { cpp_dec_float_50 pi("3.14159265358979323846264338327950288419716939937510"); auto result = pi * pi; // Set the precision slightly higher than the number of digits std::cout << std::setprecision(51) << result << std::endl; }#include <boost/multiprecision/cpp_dec_float.hpp> #include <iostream> // Let's define a type to take pi to 200 decimal places, 201 including the initial "3" using cpp_dec_float_201 = boost::multiprecision::number<boost::multiprecision::cpp_dec_float<201> >; int main() { cpp_dec_float_201 pi("3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679" "8214808651328230664709384460955058223172535940812848111745028410270193852110555964462294895493038196"); std::cout << std::setprecision(201) << pi << std::endl; }Boost.Math adds high-quality special functions that integrate well with these types from Boost.Multiprecision. For example,
boost::math::gamma,boost::math::exp, andboost::math::lgammaare available. Also, Boost.Qvm (quaternions, vectors, matrices) supports these custom precision types.The cost as you can imagine is performance, the benefit is extreme accuracy. Under the hood,
cpp_dec_float<N>storesNdecimal digits of precision, using a base-10 representation, and uses an array of limbs to manage arbitrary-length mantissas. -
Is there a Boost library that can help me with numbers like infinity, or the imaginary number that is the square root of -1?
Yes, there is support for
infinity,NaN(Not a Number), and imaginary numbers through different libraries. Boost.Math includes constants and utilities for working withinfinityandNaN, which are part of IEEE 754 floating-point standards.#include <boost/math/constants/constants.hpp> #include <limits> #include <iostream> #include <cmath> int main() { double inf = std::numeric_limits<double>::infinity(); double nan = std::numeric_limits<double>::quiet_NaN(); std::cout << "Infinity: " << inf << "\n"; std::cout << "NaN: " << nan << "\n"; // Or to test for them: if (std::isinf(inf)) std::cout << "This is infinity!\n"; if (std::isnan(nan)) std::cout << "This is NaN!\n"; }The complex functions of Boost.Math support imaginary numbers, such as the square root of -1.
#include <boost/math/complex.hpp> #include <iostream> int main() { std::complex<double> i(0.0, 1.0); std::complex<double> result = std::sqrt(std::complex<double>(-1.0, 0.0)); std::cout << "sqrt(-1) = " << result << "\n"; // outputs (0,1) }Boost.Multiprecision supports high-precision complex types, for example:
#include <boost/multiprecision/cpp_dec_float.hpp> #include <boost/multiprecision/cpp_complex.hpp> using namespace boost::multiprecision; using complex50 = cpp_complex_50; int main() { complex50 c(0, 1); auto r = sqrt(complex50(-1, 0)); std::cout << r << "\n"; // (0,1) } -
Can Boost.Multiprecision help calcuate a huge number of prime numbers?
Use the type
boost::multiprecision::cpp_intto safely store large prime numbers beyond the capacity of the standardint64_t, and the core algorithm known as the Sieve of Eratosthenes:#include <boost/multiprecision/cpp_int.hpp> #include <iostream> #include <vector> #include <cmath> #include <chrono> using boost::multiprecision::cpp_int; std::vector<cpp_int> generate_primes(size_t count) { // Rough upper bound for nth prime using approximation: n * log(n) * 1.2 size_t estimate = static_cast<size_t>(count * std::log(count) * 1.2); std::vector<bool> is_prime(estimate + 1, true); std::vector<cpp_int> primes; is_prime[0] = is_prime[1] = false; for (size_t i = 2; i <= estimate && primes.size() < count; ++i) { if (is_prime[i]) { primes.emplace_back(i); // Store as cpp_int for (size_t j = i * 2; j <= estimate; j += i) { is_prime[j] = false; } } } return primes; } int main() { size_t prime_count = 100000; // adjust this to your needs (10 million may need 6+ GB of RAM) auto start = std::chrono::high_resolution_clock::now(); std::vector<cpp_int> primes = generate_primes(prime_count); auto end = std::chrono::high_resolution_clock::now(); std::chrono::duration<double> elapsed = end - start; std::cout << "Generated " << primes.size() << " primes.\n"; std::cout << "Largest prime found: " << primes.back() << "\n"; std::cout << "Time elapsed: " << elapsed.count() << " seconds.\n"; return 0; }Running this code:
Generated 100000 primes. Largest prime found: 1299709 Time elapsed: 1.86556 seconds.- Note
-
cpp_intis overkill for small primes, but essential if you’re working with large ones, such as 512-bit cryptographic primes.
-
Am I right that Boost libraries do not improve on the performance of the standard floating point
double?Correct. Use
doubleif you can, and only use higher precision types when you’re accumulating billions of values and errors grow unbounded, or you need more than 17 digits of accuracy, or you’re solving numerically unstable equations, or you’re doing astronomy, cryptography, quantum physics, symbolic algebra, or working with scientific constants.- Note
-
A numerically unstable equation is one in which small changes or errors in input, or intermediate calculations, can lead to large errors in the final result due to the amplification of rounding or truncation errors in floating-point arithmetic. Numerical instability often arises when subtracting two nearly equal numbers (called catastrophic cancellation), dividing by very small numbers, performing many iterations where small errors accumulate, and poor choice of algorithm. A catastrophic cancellation might occur when subtracting 1.0000001 from 1.0000002 - precision and rounding errors might distort the result. Stable algorithms preserve significant digits and give reliable results even with floating-point limits.
-
What scientific numbers, similar to pi, require precision beyond that provided by the standard
double?Here is a table of the usual suspects:
Constant Typical Digits Needed Why doubleIsn’t Enoughπ (pi)
50-100+
Needed with extreme accuracy in orbital mechanics, quantum computing, etc.
e (Euler’s number)
30-100+
Used in high-precision financial models, calculus, and exponential growth systems.
γ (Euler-Mascheroni constant)
50-100+
Arises in analytic number theory and integrals.
φ (Golden ratio)
30+
Used in precise design and algorithmic ratios.
Planck’s constant (h)
25-100
Central to quantum mechanics; precise modeling demands high precision.
Fine-structure constant (α)
30-80
Key in atomic physics and fundamental interactions.
Avogadro’s number
23+
Often stored as a float, but high-accuracy simulations may demand higher precision.
Speed of light (c)
17+
For ultra-precise relativistic calculations.
Gravitational constant (G)
20-100
Known only to limited digits experimentally, but simulations may push precision.
Riemann zeta constants
30-200+
Arise in number theory and string theory.
Catalan’s constant
50+
Appears in combinatorics and integrals.
Apéry’s constant
50-200
Arises in irrationality proofs and advanced analysis.
- Note
-
Precision can become an obsession. Pi has been computed to over 100 trillion digits, but NASA’s orbital calculations use only around the first 15 digits of pi (so a
doublewould work!).
-
To avoid floating point numbers altogether, I could use fractions. For example, storing a third as 1 over 3 avoids using 0.33333 ad infinitum. Is there a Boost library that would make sense of numbers stored only as integer fractions?
Yes. Boost.Rational is a library designed specifically to represent and manipulate rational numbers — that is, numbers stored as fractions of two integers (such as, 1/3, 355/113).
It avoids floating-point approximation entirely, preserving mathematical exactness throughout arithmetic operations. The library automatically normalizes (reduces) fractions - so 3/6 would be reduced to 1/2. And it can interoperate with
int,long, or evenboost::multiprecision::cpp_int. For example:#include <boost/rational.hpp> #include <iostream> int main() { boost::rational<int> a(1, 3); // 1/3 boost::rational<int> b(2, 5); // 2/5 auto sum = a + b; // 1/3 + 2/5 = 11/15 auto product = a * b; // 1/3 * 2/5 = 2/15 std::cout << "Sum: " << sum.numerator() << "/" << sum.denominator() << "\n"; std::cout << "Product: " << product << "\n"; // prints as 2/15 // Comparison if (a < b) std::cout << "a is less than b\n"; }- Note
-
Using rational numbers there is a risk of integer overflow, so consider using large integers for inputs (
boost::multiprecision::cpp_intor similar), and this approach is not ideal for numbers known to be irrational (square root of 2, and the scientific constants listed above).
-
Can I use Boost.Multiprecision or Boost.Math to help with my project on RSA public-key encryption?
Yes. Starting with the basic algorithm for RSA (Rivest-Shamir-Adleman - the authors of the algorithm) which follows these steps:
-
Choose two large prime numbers
pandq -
Compute
n = p * q -
Compute Euler’s totient
ϕ(n) = (p-1)(q-1) -
Choose public exponent
esuch that1 < e < ϕ(n)andgcd(e,ϕ(n)) = 1 -
Compute private exponent
dsuch thate⋅d ≡ 1 mod ϕ(n) -
Now you have:
public-key = (e,n)andprivate-key = (d,n)We can now use
cpp_intfrom Boost.Multiprecision to handle arbitrary-precision integers. And, if need be, you can useis_primefrom Boost.Math for primality checks on larger randomly generated values (which you may want to add at a later date, using Boost.Random).#include <boost/multiprecision/cpp_int.hpp> #include <boost/integer/common_factor_rt.hpp> #include <iostream> using namespace boost::multiprecision; // Compute modular inverse of a modulo m using Extended Euclidean Algorithm cpp_int modinv(cpp_int a, cpp_int m) { cpp_int m0 = m, t, q; cpp_int x0 = 0, x1 = 1; while (a > 1) { q = a / m; t = m; m = a % m; a = t; t = x0; x0 = x1 - q * x0; x1 = t; } return (x1 < 0) ? x1 + m0 : x1; } int main() { // Small primes for demo cpp_int p = 61; cpp_int q = 53; cpp_int n = p * q; // n = 3233 cpp_int phi = (p - 1) * (q - 1); // φ(n) = 3120 cpp_int e = 17; // Common public exponent cpp_int d = modinv(e, phi); // Compute private key // Display keys std::cout << "Public Key (e, n): (" << e << ", " << n << ")\n"; std::cout << "Private Key (d, n): (" << d << ", " << n << ")\n"; // Create message cpp_int message = 65; std::cout << "Initial message: " << message << "\n"; // Encrypt message cpp_int encrypted = powm(message, e, n); // m^e mod n std::cout << "Encrypted message: " << encrypted << "\n"; // Decrypt message cpp_int decrypted = powm(encrypted, d, n); // c^d mod n std::cout << "Decrypted message: " << decrypted << "\n"; return 0; }- Note
-
Consider using
independent_bits_enginefrom Boost.Random for a clean way to get large random integers of fixed bit-width, and then consider very large prime numbers of perhaps 1024 bits.
-
-
What does a 1024-bit prime number look like?
Here is one:
cpp_int prime = 165918700393058288029118516503856682928352034064210292320510526037152431960844672521054555721941412725769027652540094762345484278576411078143188748708281181119556988860248537167684663864334811189453410905241474311369868568296877192226227785240656833746573473244854528133231976802973699288063056142727481235873 -
I need efficient memory storage for a real-time simulation. The use case is small counts, for example the number of carrier task forces operating in one ocean at any one time - a number which will never exceed 10 let alone 256?
A full sized int or even a byte is comically oversized for this use case. You could use the standard:
std::uint8_t num_groups;, however you might like to add some range-safety. Consider the following code as it’s memory footprint is exacty 3 bytes:#include <cstdint> #include <boost/endian/arithmetic.hpp> #include <boost/numeric/conversion/cast.hpp> struct OceanStatus { boost::endian::little_uint8_t carrier_groups; // 1 byte on disk boost::endian::little_uint8_t submarine_groups; boost::endian::little_uint8_t air_wings; void set_carrier_groups(int x) { // Guarantee 0–10 range at runtime if (x < 0 || x > 10) throw std::out_of_range("carrier group count must be 0-10"); // Safe cast to uint8_t carrier_groups = boost::numeric_cast<std::uint8_t>(x); } }; -
What library should I look at to help pack really small integers (say 2 to 4 bits each) into the minimum number of bytes possible?
The libary to evaluate is Boost.DynamicBitset, it gives you stable bit indexing, easy clearing/writing slices, guaranteed predictable ordering, and portability across CPU architectures. In particular, check out the function
to_block_rangefor exporting packed blocks. This should be easier - and safer - than hand-rolling your own masks and shifts.
Other Languages
-
Have developers written applications in languages such as Python that have successfully used the Boost libraries?
Yes, developers have successfully used Boost libraries in applications written in languages other than C++ by leveraging language interoperability features and creating bindings or wrappers.
The most notable example is the use of Boost.Python, a library specifically designed to enable seamless interoperability between C++ and Python. Boost.Python allows developers to expose C++ classes, functions, and objects to Python, enabling the use of the libraries from Python code. This has been used extensively in scientific computing, game development, and other fields where the performance of C++ is combined with the ease of Python.
-
What real world applications have combined Python with the Boost libraries?
Here are some examples:
-
Blender is a widely-used open-source 3D creation suite. It supports the entirety of the 3D pipeline, including modeling, rigging, animation, simulation, rendering, compositing, and motion tracking. Blender uses Boost libraries for various purposes, including memory management, string manipulation, and other utility functions. Blender’s Python API, which allows users to script and automate tasks, integrates with C++ code using Boost.Python.
-
PyTorch is an open-source machine learning library based on the Torch library. It is used for applications such as natural language processing and computer vision. PyTorch uses several Boost libraries to handle low-level operations efficiently. Boost.Python is used to create bindings between C++ and Python, allowing PyTorch to provide a seamless interface for Python developers.
-
OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. OpenCV’s Python bindings use Boost.Python to interface between the C++ core and Python. This allows Python developers to use OpenCV’s powerful C++ functions with Python syntax.
-
Enthought Canopy is a comprehensive Python analysis environment and distribution for scientific and analytic computing. It includes a Python distribution, an integrated development environment (IDE), and many additional tools and libraries.
-
-
Are there some solid examples of real world applications that have combined C# with the Boost libraries?
Here are some great examples:
-
In the world of game development, several projects use C++ for performance-critical components and C# for scripting and higher-level logic. The Boost libraries are often used in the C++ components, in particular to leverage their algorithms, and data structures. Unity allows the use of native plugins written in pass[C++]. These plugins can use Boost libraries for various functionalities, such as pathfinding algorithms or custom data structures, and then be called from C# scripts within Unity.
-
Financial applications often require high performance and reliability. They may use C++ for core processing and Boost libraries for tasks like date-time calculations, serialization, and multithreading. C# is used for GUI and integration with other enterprise systems. Trading platforms and risk management systems sometimes use Boost libraries for backend processing and interoperate with C# components for the user interface and data reporting.
-
Scientific computing applications that need high-performance computation often use C++ for core algorithms. C# is great for visualization, user interaction, and orchestration. Computational chemistry and physics applications sometimes use Boost for numerical computations and data handling, while C# provides the tools for managing simulations and visualizing results.
-
-
Can I see some sample code of how to wrap Boost functions to be available for use in a C# app?
The following code shows how to create a wrapper for a C++ class that uses Boost, and then calls this class from a C# application. The handling of return values and exceptions are shown too. All the class does is convert a string to upper case.
The following code was written and tested using Visual Studio 2022, with Boost version 1.88. Visual Studio has been installed with tools to create both native C++ and .NET C# apps.
In Visual Studio, create a C++ Dynamic Link Library (DLL) project,
MyDLL, and in the project properties make sure the Additional Include Directories has the path to your Boostincludefiles, and Additional Library Directories has the path to your Boostlibfiles. Most importantly in the Configuration Properties/Advanced section, make sure the Common Language Runtime Support setting is .NET Framework Runtime Support (/clr). Delete the defaultdllmain.cppfile.Create a header file,
MyClass.h, and copy in the following code:#pragma once #include <string> class MyClass { public: std::string to_upper(const std::string& input); };Create a second header file,
MyClassWrapper.h, and copy in:#pragma once #include "MyClass.h" using namespace System; public ref class MyClassWrapper { private: MyClass* instance; public: MyClassWrapper(); ~MyClassWrapper(); !MyClassWrapper(); String^ ToUpper(String^ input); };Create a new source file,
MyClass.cpp, and copy in:#include "pch.h" #include "MyClass.h" #include <boost/algorithm/string.hpp> #include <stdexcept> std::string MyClass::to_upper(const std::string& input) { if (input.empty()) { throw std::runtime_error("Input string is empty"); } return boost::to_upper_copy(input); }We use Boost.Algorithm here, to show how to engage our libraries.
Next, create a second source file,
MyClassWrapper.cpp, to expose the class to .NET:#include "pch.h" #include "MyClassWrapper.h" #include <msclr/marshal_cppstd.h> #include <stdexcept> using namespace msclr::interop; using namespace System::Runtime::InteropServices; MyClassWrapper::MyClassWrapper() { instance = new MyClass(); } MyClassWrapper::~MyClassWrapper() { this->!MyClassWrapper(); } MyClassWrapper::!MyClassWrapper() { delete instance; } String^ MyClassWrapper::ToUpper(String^ input) { try { std::string nativeInput = marshal_as<std::string>(input); std::string result = instance->to_upper(nativeInput); return gcnew String(result.c_str()); } catch (const std::exception& e) { throw gcnew ExternalException(gcnew String(e.what())); } }Now, build your DLL, and hopefully it will build correctly. If it does, close that solution. Errors are usually because of missing components, rather than faulty code.
Now create the C# application that uses the wrapper. In Visual Studio, create a C# Console app,
CppCsharp, noting that a .NET framework is part of the project, and overwrite the default with the following code.using System; class Program { static void Main() { MyClassWrapper myClass = new MyClassWrapper(); try { string result = myClass.ToUpper("hello world"); Console.WriteLine("Result: " + result); // Test with an empty string to trigger the exception result = myClass.ToUpper(""); Console.WriteLine("Result: " + result); } catch (System.Runtime.InteropServices.ExternalException e) { Console.WriteLine("Caught an exception: " + e.Message); } } }You will notice that the
MyClassWrapperdeclaration is marked as erroneous.In Visual Studio, in the Project menu, select Add Project Reference, and then use the Browse option to locate your
MyDLL.dll. You should notice the error marks disappear.Run the program, noting the initial string is converted to upper case, and the second call correctly returns the exception:
Result: HELLO WORLD Caught an exception: Input string is empty
-
Does the Java Native Interface (JNI) work with the Boost libraries?
Through the use of the Java Native Interface (JNI) or Java Native Access (JNA), developers can call Boost libraries from Java applications. It involves creating native methods in Java that are implemented in C++ and using Boost libraries as part of those implementations.
- Note
-
Similar techniques can be applied to other languages, such as R, Ruby, Perl, and Lua, using their respective foreign function interfaces (FFI) or binding libraries.
-
What is the industry consensus for the expected remaining lifespan for C++, and does any other language look like it might become the replacement for it?
The expected remaining lifespan of the C++ programming language is generally considered to be long, probably spanning several decades. While it’s difficult to assign a precise number of years, here’s an overview of the factors contributing to this consensus:
-
C++ is deeply embedded in many critical systems, including operating systems, game engines, real-time systems, financial systems, and large-scale infrastructure projects. The massive amount of existing code ensures that the language will be relevant for a long time as maintaining, updating, and interacting with this codebase will remain necessary.
-
The Boost libraries and the C++ Standard place a strong emphasis on backward compatibility, which helps ensure that older code continues to work with new versions of the language.
-
The C++ language continues to evolve, with regular updates to the standard (for example, C++11, C++14, C++17, C++20, and C++23). These updates introduce new features and improvements that keep the language modern and competitive.
-
The C++ community, including the ISO C++ committee and Boost users, are highly active, ensuring that the language adapts to new programming paradigms, hardware architectures, and developer needs.
-
High Performance - C++ remains one of the go-to languages for applications where performance is critical, such as gaming, high-frequency trading, and embedded systems. Its ability to provide low-level memory and hardware control while still supporting high-level abstractions makes it difficult to replace.
-
For system-level programming and scenarios where fine-grained control over system resources is necessary, C++ is still unmatched.
-
C++ is still widely taught in universities, especially in courses related to systems programming, algorithms, and data structures. As a teaching language, it instills principles of memory management, performance optimization, and object-oriented programming, which are valuable across many programming domains.
-
C++ has a strong presence in specialized domains such as aerospace, robotics, telecommunications, and automotive software, where reliability, real-time performance, and low-level hardware access are critical. For example, some current EV manufacturers are using C++ and Unreal Engine to develop their in-car infotainment and control systems.
-
While newer languages may rise in popularity for certain use cases, no other language currently offers the same combination of performance, control, and ecosystem that C++ provides, making it unlikely to be replaced any time soon.
Future technological shifts, such as advances in quantum computing or entirely new programming paradigms, could influence (increase or decrease) the lifespan of C++. However, given its adaptability and entrenched role in many industries, C++ is expected to evolve alongside these changes rather than be replaced by them.
-
-
If I was to learn one other language, in addition to C++, what should it be to best prepare myself for an uncertain future?
Python is often the top recommendation due to its versatility, simplicity, and wide application in growing fields like artificial intelligence (AI), machine learning (ML), rapid prototyping, and data science. And Boost.Python is there to help you integrate with the Boost libraries. Rust is another strong contender, especially if you are interested in systems programming and are looking for reliability and security. If you see the future as more cloud computing, then Go makes a strong case for itself. And let’s not forget that so much computing is now web based, so JavaScript deserves a mention here too. All of these languages offer valuable resources that complement C++ and prepare you for an uncertain future.
Production and Debug Builds
-
What is the value of using
BOOST_ASSERTorBOOST_STATIC_ASSERTover the Standard Library assert macros?There are a few advantages of using the Boost asserts, available in
<boost/assert.hpp>, including thatBOOST_ASSERTis fully customizable usingBOOST_ENABLE_ASSERT_HANDLER, which can be used to log extra data or stack traces, and there is better integration with Boost.Test.BOOST_STATIC_ASSERTis best utilized when using older C++ standards (pre-C++17), or you are using deeply templated code. You might also prefer the Boost macros if you are engaging the features of other Boost libraries and are looking for consistent tooling. For a fuller discussion, refer to Boost Macros. -
For maximum performance, is it good practice to remove, or comment out, the `BOOST_ASSERT`s for the final production code, or do they simply not get compiled into anything so there is no performance cost for leaving them as is?
By default,
BOOST_ASSERTmacros are completely removed from the compiled binary whenNDEBUGis defined, just like the standard assert macro. IfNDEBUGis not defined aBOOST_ASSERT(x)will expand, usually to anassertion_failed()if the assert condition fails. If NDEBUG is defined it expands to((void)0)so nothing is generated. Boost does provide theBOOST_DISABLE_ASSERTSmacro, which has the same effect on Boost asserts asNDEBUG- but will leave other asserts alone. -
What is usually considered to be best practices in handling assertions that fire with a production build?
Instead of throwing an exception when an assert fails, it is often the best practice to log the failure. For example, here is a custom assert handler using the features of Boost.Log to record the event:
#include <boost/assert.hpp> #include <boost/log/trivial.hpp> #include <boost/log/utility/setup/file.hpp> #include <boost/log/utility/setup/console.hpp> #include <boost/log/utility/setup/common_attributes.hpp> #include <boost/log/expressions.hpp> #include <sstream> #include <cstdlib> namespace logging = boost::log; // Configure Boost.Log (call once at startup) void init_logging() { logging::add_common_attributes(); // Console output logging::add_console_log( std::clog, logging::keywords::format = "[%TimeStamp%] [%Severity%] %Message%" ); // File output logging::add_file_log( logging::keywords::file_name = "assert_failures_%N.log", logging::keywords::rotation_size = 10 * 1024 * 1024, // 10 MB logging::keywords::format = "[%TimeStamp%] [%Severity%] %Message%" ); } // Custom handler for BOOST_ASSERT namespace boost { void assertion_failed(char const* expr, char const* function, char const* file, long line) { std::ostringstream oss; oss << "BOOST_ASSERT failed!\n" << " Expression: " << expr << "\n" << " Function: " << function << "\n" << " File: " << file << "\n" << " Line: " << line; BOOST_LOG_TRIVIAL(error) << oss.str(); std::abort(); // Optional: comment out if soft fail is desired } }An example use of this handler would be:
#include <boost/assert.hpp> #include <iostream> // Declare logging initializer void init_logging(); void test_logic(int value) { BOOST_ASSERT(value >= 0); std::cout << "Value is: " << value << std::endl; } int main() { init_logging(); std::cout << "Testing BOOST_ASSERT with value = 42..." << std::endl; test_logic(42); std::cout << "Testing BOOST_ASSERT with value = -1..." << std::endl; test_logic(-1); // Logs to file and console, then aborts return 0; } -
What should I be aware of when moving from a Debug to a Production release?
Use this checklist to ensure your application correctly integrates Boost libraries across Debug and Release configurations.
-
Linking and Compatibility
-
Link with the correct Boost library variant (
-gdfor Debug, none for Release). -
Ensure runtime settings (Debug CRT or Release CRT) match Boost binaries.
-
Avoid mixing Debug-built Boost libraries with Release-built applications.
-
Macro Definitions and Configuration
-
Define
BOOST_DEBUGin Debug builds to enable extra runtime checks (if applicable). -
Define
BOOST_DISABLE_ASSERTSin Release builds to removeBOOST_ASSERTchecks. -
Optionally define
BOOST_ENABLE_ASSERT_HANDLERto install custom assertion handlers. -
Review conditional macros like
BOOST_NO_EXCEPTIONS,BOOST_NO_RTTI, etc. -
Assertions and Diagnostics
-
Use
BOOST_ASSERTfor critical development-time checks. -
Consider diagnostic logging using
BOOST_LOG_TRIVIAL. -
Ensure failing assertions are tested and logged in Debug builds.
-
Debugging and Tooling
-
Run AddressSanitizer, Valgrind, or Visual Leak Detector in Debug builds. Refer to Contributor Guide: Sanitizers.
-
Confirm Boost.Pool, Boost.Container, and alloc-heavy libraries don’t leak memory.
-
Validate Boost.Thread, Boost.Asio, and Boost.Fiber components using thread sanitizers.
-
Performance Awareness
-
Avoid benchmarking with Debug builds — optimization is disabled.
-
Use Release builds to test compile times for Boost.Mp11, Boost.Spirit, and any heavy use of templates.
-
Validate any
BOOST_FORCEINLINEorBOOST_NOINLINEeffects in both builds. -
Unit Testing
-
Run the full suite of unit tests in both Debug and Release.
-
Ensure no logic is only covered by Debug-only paths or assertions.
-
Use Boost.Test to validate results across optimization levels.
-
-
Typically, how should I set up a CMake file to handle Debug and Release builds?
Here’s an example of how to set up your
CMakeLists.txtto handleBOOST_ASSERTcorrectly by toggling behavior based on the build type (Debug or Release). The example includes linking with some sample libraries (Boost.Log, Boost.System and Boost.Thread):cmake_minimum_required(VERSION 3.10) project(MyBoostApp) # Set your C++ standard set(CMAKE_CXX_STANDARD 17) set(CMAKE_CXX_STANDARD_REQUIRED ON) # Enable debug symbols for Debug mode set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -g") # Link Boost (adjust components as needed) find_package(Boost REQUIRED COMPONENTS log log_setup system thread) target_link_libraries(MyBoostApp PRIVATE Boost::log Boost::log_setup Boost::system Boost::thread ) add_executable(MyBoostApp main.cpp) target_include_directories(MyBoostApp PRIVATE ${Boost_INCLUDE_DIRS}) target_link_libraries(MyBoostApp PRIVATE ${Boost_LIBRARIES}) # Enable BOOST_ASSERT in Debug, disable in Release target_compile_definitions(MyBoostApp PRIVATE $<$<CONFIG:Debug>:BOOST_ENABLE_ASSERT_HANDLER> $<$<CONFIG:Release>:NDEBUG> ) # Optional: You can define a custom assert handler in debug builds # by linking a file like the assert handler shown above that defines `boost::assertion_failed`
Reflection
-
Is there a native library or system that approximates the capabilities of .NET System.Reflection?
Reflection in .NET is the ability of a program to inspect and manipulate its own structure and metadata at runtime. Think of reflection as a runtime mirror — it lets a program look at itself and act accordingly. Boost does not have a full runtime reflection system like .NET’s System.Reflection, but it does include several libraries and utilities that provide partial or compile-time reflection capabilities — the kind that are most practical and efficient in C++. The closest Boost comes to real reflection is encapsualted in Boost.Describe. This library allows you to describe the structure of a class — its members, base classes, and enums — at compile time, so you can iterate over them generically. Internally, Boost.Describe uses the features of Boost.Mp11.
Other libraries that you might find value in include Boost.Pfr (Precise Function Reflection), which lets you reflect on structure fields without macros or metadata, using clever template magic. For richer type information there is Boost.TypeIndex and Boost.CallableTraits, and for metaprogramming there is Boost.Mp11, Boost.Fusion, and Boost.Hana.
-
Are there plans to extend Reflection further into Boost or the Standard C++ Library?
The short answer is yes, into the Standard, but not yet. There are some niggling downsides to enabling full reflection, including slower than normal code, more difficult code maintenance and debugging, and string related issues (as string names are relied on). The standard work is known as the Reflection TS (Technical Specification).
-
Can you show me example code demonstrating how to use Boost.Describe for Reflection?
The following example shows how Boost.Describe and Boost.Mp11 work together to achieve something close to automatic runtime reflection:
#include <boost/describe.hpp> #include <boost/mp11.hpp> #include <iostream> // Describe a simple struct struct User { int id; std::string name; }; // Generate reflection metadata BOOST_DESCRIBE_STRUCT(User, (), (id, name)) // Print fields using Boost.MP11 iteration template <typename T> void print_fields(const T& obj) { boost::mp11::mp_for_each<boost::describe::describe_members<T, boost::describe::mod_public>>( [&](auto D) { std::cout << D.name << " = " << obj.*D.pointer << "\n"; }); } int main() { User u{ 42, "Ada" }; print_fields(u); } -
Can you show me example code demonstrating how to use Boost.PFR for Reflection?
Boost.Pfr provides the
iofunction for automatic input/output stream operators (<<and>>) for aggregate types — meaning you can print or read structs directly without manually defining stream operators. It reflects all public fields of a type at compile time (without macros or boilerplate), producing readable output like {field1, field2, field3} automatically, for example:#include <boost/pfr.hpp> #include <iostream> struct User { int id; std::string name; double balance; }; int main() { User u{ 42, "Alice", 100.5 }; std::cout << "As tuple: " << boost::pfr::io(u) << "\n"; }
Releases
-
How do I download the latest libraries?
Go to Boost Downloads.
-
What do the Boost version numbers mean?
The scheme is x.y.z, where x is incremented only for massive changes, such as a reorganization of many libraries, y is incremented whenever a new library is added, and z is incremented for maintenance releases. y and z are reset to 0 if the value to the left changes
-
Is there a formal relationship between Boost.org and the C++ Standards Committee?
No, although there is a strong informal relationship in that many members of the committee participate in Boost, and the people who started Boost were all committee members.
-
Will the Boost.org libraries become part of the next C++ Standard?
Some might, but that is up to the standards committee. Committee members who also participate in Boost will definitely be proposing at least some Boost libraries for standardization. Libraries which are "existing practice" are most likely to be accepted by the C++ committee for future standardization. Having a library accepted by Boost is one way to establish existing practice.
-
Is the Boost web site a commercial business?
No. It is a non-profit.
-
Why do Boost headers have a .hpp suffix rather than .h or none at all?
File extensions communicate the "type" of the file, both to humans and to computer programs. The '.h' extension is used for C header files, and therefore communicates the wrong thing about C++ header files. Using no extension communicates nothing and forces inspection of file contents to determine type. Using
.hppunambiguously identifies it as C++ header file, and works well in practice. -
How do I contribute a library?
Refer to the Contributor Guide. Note that shareware libraries, commercial libraries, or libraries requiring restrictive licensing are all not acceptable. Your library must be provided free, with full source code, and have an acceptable license. There are other ways of contributing too, providing feedback, testing, submitting suggestions for new features and bug fixes, for example. There are no fees for submitting a library.
Safe C++
-
I use Boost Libraries in my current projects. What do I need to know about Safe C++?
Retrofitting the C++ language with memory-safe constructs has proven to be daunting. The Safe C++ proposal for a memory-safe set of operations is currently in a state of indefinite hiatus. For more information, including current safe coding practices, refer to Contributors FAQ: Safe C++. For terminology - refer to Glossary: S.
Smart Pointers
-
What different types of smart pointers are there?
The Boost.SmartPtr library provides a set of smart pointers that helps in automatic and appropriate resource management. They are particularly useful for managing memory and provide a safer and more efficient way of handling dynamically allocated memory. The library provides the following types of smart pointers:
-
boost::scoped_ptr: A simple smart pointer for sole ownership of single objects that must be deleted. It’s neither copyable nor movable. Deletion occurs automatically when thescoped_ptrgoes out of scope. -
boost::scoped_array: Similar toscoped_ptr, but for arrays instead of single objects. Deletion occurs automatically when thescoped_arraygoes out of scope. -
boost::shared_ptr: A reference-counted smart pointer for single objects or arrays, which automatically deletes the object when the reference count reaches zero. Multipleshared_ptrcan point to the same object, and the object is deleted when the lastshared_ptrreferencing it is destroyed. -
boost::shared_array: Similar toshared_ptr, but for arrays instead of single objects. -
boost::weak_ptr: A companion toshared_ptrthat holds a non-owning ("weak") reference to an object that is managed byshared_ptr. It must be converted toshared_ptrin order to access the referenced object. -
boost::intrusive_ptr: A smart pointer that uses intrusive reference counting. Intrusive reference counting relies on the object to maintain the reference count, rather than the smart pointer. This can provide performance benefits in certain situations, but it requires additional support from the referenced objects. -
boost::enable_shared_from_this: Provides member functionshared_from_this, which enables an object that’s already managed by ashared_ptrto safely generate moreshared_ptrinstances that all share ownership of the same object. -
boost::unique_ptr: A smart pointer that retains exclusive ownership of an object through a pointer. It’s similar tostd::unique_ptrin the C++ Standard Library.
-
-
Can you give me a brief coding overview of how to use smart pointers efficiently?
There are several types of smart pointers with different characteristics and use cases, so use them appropriately according to your program’s requirements. Here are some common examples:
A
shared_ptris a reference-counting smart pointer, meaning it retains shared ownership of an object through a pointer. When the lastshared_ptrto an object is destroyed, the pointed-to object is automatically deleted. For example:#include <boost/shared_ptr.hpp> void foo() { boost::shared_ptr<int> sp(new int(10)); // Now 'sp' owns the 'int'. // When 'sp' is destroyed, the 'int' will be deleted. }Note that
shared_ptrobjects can be copied, meaning ownership of the memory can be shared among multiple pointers. The memory will be freed when the last remainingshared_ptris destroyed. For example:#include <boost/shared_ptr.hpp> void foo() { boost::shared_ptr<int> sp1(new int(10)); // Now 'sp1' owns the 'int'. boost::shared_ptr<int> sp2 = sp1; // Now 'sp1' and 'sp2' both own the same 'int'. // The 'int' will not be deleted until both 'sp1' and 'sp2' are destroyed. }A
weak_ptris a smart pointer that holds a non-owning ("weak") reference to an object managed by ashared_ptr. It must be converted toshared_ptrin order to access the object. For example:#include <boost/shared_ptr.hpp> #include <boost/weak_ptr.hpp> void foo() { boost::shared_ptr<int> sp(new int(10)); boost::weak_ptr<int> wp = sp; // 'wp' is a weak pointer to the 'int'. // If 'sp' is destroyed, 'wp' will be able to detect it. }A
unique_ptris a smart pointer that retains exclusive ownership of an object through a pointer. It’s similar tostd::unique_ptrin the C++ Standard Library. For example:#include <boost/interprocess/smart_ptr/unique_ptr.hpp> void foo() { boost::movelib::unique_ptr<int> up(new int(10)); // Now 'up' owns the 'int'. // When 'up' is destroyed, the 'int' will be deleted. }
Standard C++ Library
-
Where can I find the most complete documentation on the C++ Standard Library?
Here, the C++ Standard Library. The Search feature is useful for locating individual components.
-
How can I be sure when I should use a Boost library or a component of the Standard Library?
Most Boost libraries provide useful and advanced functionality unavailable in the Standard Library. A few Boost libraries have indeed been superseded by the Standard Library, but remain in Boost for backwards compatibility. To determine which you should use, given the choice, consider working through the following process.
- Note
-
When a Boost library is included in the Standard Library, not all of the functionality provided is necessarily standardized. For example, Boost.System has been standardized but still contains additional functionality not available in the standard. Although standardization might include all of the functionality of a Boost library, performance is not always identical and it can be of value to use the Boost version for higher performance (for example, Boost.Regex). In a few cases, the whole of the Boost library is standardized and the Boost version does not improve on performance (for example, Boost.Thread).
-
Check the Boost library documentation, as their relationship to the Standard Library is sometimes documented. Both the Overview and the Release Notes are good sources of information for mentions of standardization.
-
The C++ Standard Library is also well documented. Check to see if the functionality you are looking for is now part of the standard. If you have specific features in mind, comparing the Boost and Standard library functions and classes should provide you with a definitive answer on which to use.
-
If you are less certain of the specific features you need, developers often discuss the status and relevance of Boost libraries in comparison to the standard. Browse, or ask a question in, Stack Overflow, Reddit, or the Boost Developers Mailing List.
-
If you want to dig into the source code, check the activity in the Boost library’s GitHub repository. Libraries that have been largely superseded have less recent activity compared to those still actively developed and extended. Also check Release Notes for mentions of deprecations or recommendations.
-
Current examples of libraries where you should now use the Standard Library include Boost.SmartPtr (use
std::shared_ptr,std::unique_ptretc.), Boost.Thread (usestd::thread), Boost.Chrono (usestd::chrono), and Boost.Random (usestd::rand). Referring to the documentation for these might help show the language used when discussing the relationship with the Standard Library.
-
-
Are there any Boost libraries currently being considered for inclusion in the Standard Library?
Yes, currently the functionality of two Boost libraries are being considered:
-
Boost.Lambda2 : for details refer to Adding functionality to placeholder types
-
Boost.Fiber : for details refer to fiber_context - fibers without scheduler
-
-
What is the current status of the Standard Library and when is the next release?
C++ 2026 is slated as the next full release, for full details refer to Current Status.
-
What are the big ticket items that should appear in the C++26 Standard Library?
Here is a table of the most compelling:
Feature Description Contracts
Language support for preconditions, postconditions, and assertions (
expects,ensures). Major safety and correctness feature long awaited since C++20 removal.Static Reflection
Compile-time introspection of types, members, functions, attributes. Enables metaprogramming without template hacks.
Pattern Matching
Functional-style
match/inspectsyntax for variant-like types and structured branching.std::expectedImprovements & Monadic UtilitiesFunctional chaining helpers (
and_then,transform, etc.) across error-handling types.Senders / Receivers (
std::execution)Modern async execution model replacing ad-hoc futures. Foundation for high-performance async C++.
std::generatorCoroutine-based lazy range generator for pipelines and streaming data.
std::embed(Binary Resource Embedding)Embed files/resources directly into binaries at compile time. Great for games, ML, embedded, tooling.
Hazard Pointers / RCU
Lock-free memory reclamation primitives for high-performance concurrency.
Standard Units & Quantities Library
Type-safe physical units (meters, seconds, etc.). Prevents unit conversion bugs.
std::flat_map/std::flat_setCache-friendly associative containers (vector-based).
std::inplace_vectorFixed-capacity vector with no heap allocation. Important for real-time systems.
Freestanding Library Expansion
Makes C++ usable in kernels, embedded, GPUs without full runtime.
constexpr expansion (“constexpr everything”)
Many standard library components now usable at compile time.
Improved Module Ecosystem
Numerous refinements to make modules practical for large codebases.
Unicode improvements
Better text encoding and Unicode handling across the standard library.
-
What are the big ticket items that missed the C++26 Standard Library, but may appear in the 2029 release?
Several initiatives are likely candidates, but need more time:
Feature Description Why it missed 26 Pattern Matching v2 (full algebraic matching)
Extends the accepted pattern matching to support destructuring, guards, exhaustive checking, and more functional-style power.
Initial version was accepted, but the full vision is large and still evolving.
Metaclasses / Compile-time Classes
A revolutionary feature allowing user-defined “kinds of classes” (value types, interfaces, etc.) enforced by the compiler.
Huge design space and tooling impact. Needs more experience from Reflection first. Perhaps more long-term than likely for C++29.
Unified Call Syntax (UFCS)
Allows
obj.func(x)to call free functions as if they were members. Improves discoverability and pipeline style.Lots of bikeshedding over lookup rules and ambiguity.
Executor refinements & Networking TS integration
Completing the networking library on top of Senders/Receivers.
Senders/Receivers landed late; networking integration needs time to bake.
Trivial Relocation
Lets objects be safely moved with
memcpywhen possible, which should lead to a massive performance win for containers.Deep ABI and library implications; needed more consensus.
std::async_scopeand structured concurrencyHigh-level lifetime management for async tasks (similar to modern languages).
Depends on ecosystem experience with Senders/Receivers first.
SIMD Everywhere (
std::simdexpansion)Making vectorization first-class and pervasive across the standard library.
Big scope and ongoing performance experimentation.
Language support for contracts tooling modes
The accepted Contracts feature is the “MVP”. Advanced tooling levels and build modes are still being designed.
Needed to ship a minimal version first.
Compile-time Reflection v2 (code injection / metaprogramming)
Extends reflection to allow generating new declarations.
Committee intentionally staged reflection to reduce risk.
Pattern-based error handling (try expressions)
Expression-based error propagation similar to Rust.
Interaction with exceptions and
expectedstill debated.std::status_code/ modern error systemA zero-overhead alternative to exceptions and
std::error_code.Competes with existing mechanisms; consensus not complete.
Heterogeneous lookup everywhere
Transparent hashing/comparisons across more containers and algorithms.
Lots of small but invasive library changes.
-
Are there themes to a release of the Standard?
To an extent, C++20 was the "Coroutines and Ranges" release, then C++23 was a cleanup release. C++26 is shaping up to be the "Safety and Async and Metaprogramming" release. Perhaps C++29 will be the "Performance, Networking, and Compile-time Metaprogramming Superpowers" release.
Templates
-
What are C++ templates?
C++ templates are a powerful feature of the language that allows for generic programming. They enable the creation of functions or classes that can operate on different data types without having to duplicate code.
-
What are the benefits and drawbacks of using templates in C++?
The benefits of using templates include code reusability, type safety, and the ability to use generic programming paradigms. The drawbacks include more complex syntax, potentially increased compile times, difficult-to-understand error messages, and other complexities associated with template metaprogramming.
-
What are function templates in C++?
Function templates are functions that can be used with any data type. You define them using the keyword template followed by the template parameters. Function templates allow you to create a single function that can operate on different data types, for example:
template<typename T> T add(T a, T b) { return a + b; }This will work if both types of the input are the same (ints, floats, chars even). If you want to add two different types together, then use:
template<typename T, typename U> auto add(T a, U b) { return a + b; }This works, even with
add('A', 2);- which gives67as a result. -
Apart from function templates, are there other types of templates?
Yes, there are many other types of template, including class templates that define generic object types or data structures. For example:
template<typename T> class Box { T value; };Usage of this class template might be
Box<int>orBox<double>. Class templates usually require explicit type declaration, whereas function templates usually let the compiler infer the type.Whereas function and class templates are the most used, the following table shows how many types of template there are now:
Template Type Purpose Function Template
Generic algorithms
Class Template
Generic objects/data structures
Variable Template
Generic constants/variables
Alias Template
Generic type aliases
Member Function Template
Generic methods inside classes
Template Template Parameter
Templates that accept templates
Non-Type Template
Compile-time values as parameters
Constrained Template
Restrict allowed template types
Lambda Template
Generic anonymous functions
Metaprogramming Template
Compile-time computation
For more details on using these template types refer to the documentation for Boost.Mp11 and Boost.Hana.
-
What is template specialization in C++?
Template specialization is a feature of C++ templates that allows you to define a different implementation of a template for a specific type or set of types. It can be used with both class and function templates. For example, the following code shows a specialization template for
bool, which we want to handle differently:#include <iostream> // Primary template template<typename T> void print(T value) { std::cout << "Generic: " << value << "\n"; } // Specialization for bool template<> void print<bool>(bool value) { std::cout << "Boolean: " << (value ? "true" : "false") << "\n"; } int main() { print(42); print(3.14); print(true); print(false); }Run this code and you will see the difference:
Generic: 42 Generic: 3.14 Boolean: true Boolean: false -
What is considered good practice for naming template types - I see "T" and "U" often used for example - is this considered explicit enough?
T,UandVare traditional and perfectly acceptable for small, obvious templates, and usually used in that order for first, second and third template type. But for more complex code, descriptive names are usually better. For example the following code is not that helpful:template<typename T, typename U, typename V> void connect(T a, U b, V c);This might be better:
template<typename SocketType, typename BufferType, typename HandlerType> void connect(SocketType socket, BufferType buffer, HandlerType handler);Notice how PascalCase and the word
Typeare used, by convention, in the type names. -
How can I use templates to implement a generic sort function in C++?
Here’s an example of how you might use a function template to implement a generic sort function, working with Boost.Range, so any type that is supported by this library can be sorted using the following function:
#include <boost/range/iterator_range.hpp> // Bubble sort using Boost.Range-compatible interface template<typename Range> void bubble_sort_range(Range& r) { using std::begin; using std::end; using Iterator = typename boost::range_iterator<Range>::type; using Category = typename std::iterator_traits<Iterator>::iterator_category; // Enforce random access iterators at compile time BOOST_STATIC_ASSERT((std::is_base_of<std::random_access_iterator_tag, Category>::value)); Iterator first = boost::begin(r); Iterator last = boost::end(r); if (first == last) return; bool swapped = true; while (swapped) { swapped = false; for (Iterator it = first; it + 1 != last; ++it) { if (*(it + 1) < *it) { std::iter_swap(it, it + 1); swapped = true; } } --last; } } // Usage example: #include <iostream> #include <vector> int main() { std::vector<int> nums = { 9, 3, 7, 1, 4, 6, 12, 21, 14, 13, 11, 9, -1, -4 }; bubble_sort_range(nums); for (int n : nums) std::cout << n << " "; std::cout << "\n"; std::vector<std::string> names = { "charlie", "alice", "bob", "pete", "vanessa", "dave", "alexi"}; bubble_sort_range(names); for (const auto& name : names) std::cout << name << " "; std::cout << "\n"; }Running the example you should get the output:
-4 -1 1 3 4 6 7 9 9 11 12 13 14 21 alexi alice bob charlie dave pete vanessa- Note
-
The use of templates for sorting is given as an example only, the
std::sort,std::stable_sort, andstd::spreadsortare super efficient and should be used whenever possible. However, if you have a special process you would like to apply to different types of ranges, this templated approach may work well for you. For specialized sorts, refer to Boost.Sort.
Types
-
The Boost Libraries have been criticized for using Boost-specific types, do all the libraries use Boost types or do some use standard integers, floats, and strings to name a few of the most-used types?
This question comes up often when people start using Boost seriously. The short answer is "no", not all Boost libraries use Boost-specific types. In fact, many Boost libraries rely primarily on standard types such as
int,double,std::string, andstd::vector. Boost types generally appear only where they add functionality the standard library didn’t have at the time — or still doesn’t.Most libraries use standard types, such as: Boost.Math, Boost.Algorithm, Boost.Random, Boost.Accumulators, Boost.Multiprecision, Boost.Range, Boost.Geometry, Boost.PFR, Boost.Describe.
A few libraries use minimal specific types, such as Boost.System, Boost.ProgramOptions.
The following libraries were introducted before Standard C++ introduced equivalents: Boost.Optional, Boost.Variant, Boost.Function, Boost.Any, Boost.Filesystem, Boost.SmartPtr.
In some libraries Boost-specfic types are needed for some issues like portability, allocator support, or async control. Such libraries inlude the popular Boost.Asio, and others including Boost.Coroutine2, Boost.Context, Boost.Lockfree.
For the libraries that require meta-types at compile time, these do require mostly Boost-specific types: Boost.Mp11, Boost.Hana, Boost.TypeIndex, Boost.StaticAssert.
-
Can you give me some examples of types added to Boost libraries?
In Boost.Asio the type
boost::asio::contextwas added to support a low-level async framework, though does use standard-compatible I/O buffers. In Boost.System,boost::system::error_codewas added to support location metadata not available in the standard. In Boost.Optional there is the typeboost::optional<T>, which is now available in the standard library asstd::optional- but was not available at the time Boost.Optional was released. -
If I am updating an older version of a codebase, but am not updating the C++ Standard used for that codebase, does it make sense to use Boost libraries?
Boost libraries will provide you with some version independance. For example
std::shared_ptrandstd::optionalare not available before the C++ 11 Standard, using Boost.SharedPtr and Boost.Optional should provide a robust approach to an update of older code. -
What are the issues with
std::stringthat are addressed by Boost libraries such as Static-String, String-Algo, or String-View?The
std::stringis great for general-purpose English or programming string handling, but has limitations in several key areas: performance (it requires frequent heap allocations and copies), immutability/safety (it can be unintentionally modified or shared), internationization (foreign languages), and feature gaps (it lacks certain high-level string algorithms or fixed-capacity behavior).For embedded systems, real-time applications, and performance-critical loops consider using Boost.StaticString as it provides a compile-time fixed-capacity string (
boost::static_string<N>) that eliminates heap allocations.For multi-language software and UTF-8 processing, consider using Boost.Locale for locale-aware comparisons, formatting, and conversions.
When working with configuration files, command-line tools, log or protocol parsing - or more advanced tasks such as data validation and pattern recognition - consider the Boost.StringAlgo, Boost.Regex, Boost.Xpressive, or Boost.LexicalCast libraries. These libraries offer hundreds of algorithms, views, conversions that will avoid the tedious task of reimplementing string utilities.
The Boost.StringView library has now been superceded by
std::string_view, available from C++ 17. -
Can you show me example code where standard integers and Boost.Multiprecision code work well together?
The following code shows automatic promotion (
big_int += small_int), arbitrary precision (cpp_intgrows as large as is needed), high-precision floating point (area = high_precision_pi * radius * radius), and interoperability (approx_areaconversion):#include <iostream> #include <boost/multiprecision/cpp_int.hpp> #include <boost/multiprecision/cpp_dec_float.hpp> namespace mp = boost::multiprecision; int main() { // --- 1. Standard integer and multiprecision integer --- std::int64_t small_int = 42; mp::cpp_int big_int = 1; // Multiply big_int by a large factor for (int i = 0; i < 50; ++i) big_int *= 10; // No overflow — arbitrary precision! // Add standard integer directly — implicit promotion works big_int += small_int; std::cout << "Big integer (with 42 added): " << big_int << "\n\n"; // --- 2. Using multiprecision floats with standard numeric types --- mp::cpp_dec_float_50 high_precision_pi = 3.14159265358979323846264338327950288419716939937510; double radius = 2.5; // You can mix standard and multiprecision floats seamlessly mp::cpp_dec_float_50 area = high_precision_pi * radius * radius; std::cout << std::setprecision(40); std::cout << "Area of circle (high precision): " << area << "\n\n"; // --- 3. Conversion back to standard types --- // Note: Narrowing conversions can lose precision double approx_area = static_cast<double>(area); std::cout << "Area (as double): " << std::setprecision(16) << approx_area << "\n"; // --- 4. Interoperation example: sum of large values --- mp::cpp_int total = 0; for (std::int64_t i = 1; i <= 1'000'000; ++i) total += i; // summing using high-precision integer std::cout << "\nSum of first 1,000,000 integers: " << total << "\n"; }Running this code should give you:
Big integer (with 42 added): 100000000000000000000000000000000000000000000000042 Area of circle (high precision): 19.63495408493620697498727167840115725994 Area (as double): 19.63495408493621 Sum of first 1,000,000 integers: 500000500000Boost.Multiprecision is designed to seamlessly extend the built-in numeric types, so you can mix
std::int,std::uint64_t,double, and multiprecision types freely — the library’s operator overloads handle promotion automatically. Typically, in scientific computing (very large floating point numbers)cpp_dec_float_50is combined withdouble, and for working with very large integers (say boundary values), combinecpp_intwithstd::int64_torstd::size_t. -
I am having trouble with a multi-platfrom project that requires strings in UTF-8 format, but with Windows APIs requiring UTF-16?
You should conside using Boost.Nowide, a library that makes Windows Unicode handling sane! This library provides UTF-8 versions of
fopen,std::cout, as well as file I/O and environmental variables. It also provides the crucial automatic conversion to UTF-16 when calling Windows APIs. You might also find Boost.Locale useful if internationalization is required, Boost.StaticString, and thesmall_vectortype of Boost.Container for efficient short-string handling. -
Storage space is of the essence in the real-time app I am building, are there Boost libraries that can provide small integers, specifying 8 or 16 bits and no more storage than that is allocated?
For byte level efficiency look at Boost.Endian, this library gives you precise control over both integer size and alignment. It also provides cross-platfrom compatibility, if that is important. For example,
boost::endian::little_int8_t smallCount;will always be 8 bit. Boost.Multiprecision does provide for declaring small integers as low as 8 bits, but is not so memory efficient. If your goal is to save overall memory, not just per-number bytes, check out Boost.Container, as it supports small-vector optimization and no heap allocations.